DataX导入Nginx日志到Apache Doris进行日志分析
本文由 PowerData 谢帮桂贡献
姓名:谢帮桂
花名:谢帮桂
微信:xc606060_
年龄:90 后
工作经验:5-10 年
工作内容:数仓, 数分
自我介绍:美联物业数仓负责人,主要负责数仓规划和数据开发,下方是作者帅照喔。

全文共 4914 个字,建议阅读 18 分钟
社区线下活动预告!
小伙伴们速速报名,6 月 17 我们上海见!!!
活动地址:徐汇区南丹路 169 号 景莱酒店 2 层

前言
Apache Doirs 2.0 Alpha1 版本已经实现了倒排索引功能,可以实现在千亿级数据中快速对中文关键字日志检索,实现日志监控,本文主要实践利用 Datax 进行日常 Nginx 日志导入到 Doirs 中进行日志分析测试,适合单机日志或文本采集分析场景。
组件版本
Apache Doirs 2.0 alpha1 版本
DataX 最新版本
Doris 2.0 版本说明
Apache Doris 2.0.0 alpha1 版本是 2.0 系列的首个版本,包含了倒排索引、高并发点查询、冷热分层、Pipeline 执行引擎、全新查询优化器 Nereids 等众多重要特性,主要是作为最新特性的功能验证。因此建议在新的测试集群中部署 2.0.0 alpha1 版本进行测试,但不应部署在生产集群中。
版本重要特性:
半结构化数据存储与极速分析
全新倒排索引:支持全文检索以及更加高效的等值查询、范围查询
增加了字符串类型的全文检索支持英文、中文分词
支持字符串类型和字符串数组类型的全文检索
支持字符串、数值、日期时间类型的等值查询和范围查询
支持多个条件的逻辑组合,不仅支持 AND,还支持 OR 和 not
在 esrally http 日志基准测试中,与 Elasticsearch 相比效率更高:数据导入速度提高了 4 倍,存储资源消耗减少了 80%,查询速度提高了 2 倍以上
参考文档:https://doris.apache.org/zh-CN/docs/dev/data-table/index/inverted-index
安装步骤
安装 Doirs2.0 alpha1 版本
linux 某节点下输入
curl https://doris.apache.org/download-scripts/2.0.0-alpha1/download_x64_tsinghua.sh | sh
下载的文件夹里已经有编译好的 FE 和 BE 文件夹,分别同步到集群节点,修改 fe 和 be 的 conf 里配置就可以使用,直接按官网文档安装步骤进行部署。
安装 Datax
直接官网下载编译,可以只编译需要的 reader 和 writer 的连接器,本文需要 txtfilereader 和 doriswriter。
详细过程
nginx 日志格式
下面是 Nginx access.log 日志文件格式,包括 error.log 基本大差不差。
192.168.1.10 - - [30/Apr/2022:11:24:39 +0800] "GET /api/data HTTP/1.1" 200 438 "-" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36" "-"
192.168.1.10 - - [30/Apr/2022:11:25:32 +0800] "POST /login HTTP/1.1" 403 187 "-" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36" "-"
192.168.1.10 - - [30/Apr/2022:11:26:14 +0800] "GET /css/style.css HTTP/1.1" 304 0 "https://www.example.com/" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36" "-"
192.168.1.10 - - [30/Apr/2022:11:27:06 +0800] "GET /images/logo.png HTTP/1.1" 200 2048 "https://www.example.com/" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36" "-"
192.168.1.10 - - [30/Apr/2022:11:28:03 +0800] "GET / HTTP/1.1" 200 1234 "-" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36" "-"
192.168.1.10 - - [30/Apr/2022:11:29:17 +0800] "GET /products/123 HTTP/1.1" 404 0 "-" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36" "-"
192.168.1.10 - - [30/Apr/2022:11:30:29 +0800] "GET /about HTTP/1.1" 301 0 "-" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36" "-"
192.168.1.10 - - [30/Apr/2022:11:31:44 +0800] "GET /contact HTTP/1.1" 302 0 "-" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36" "-"
192.168.1.10 - - [30/Apr/2022:11:32:57 +0800] "GET /faq HTTP/1.1" 200 823 "-" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36" "-"
192.168.1.10 - - [30/Apr/2022:11:34:10 +0800] "GET /downloads/file.zip HTTP/1.1" 200 98432 "https://www.example.com/" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36" "-"
127.0.0.1 - - [03/May/2022:12:00:47 +0800] "GET /byhsyyfront/byPages/ HTTP/1.1" 304 0 "-" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36" "-" "0.025" "0.025"
127.0.0.1 - - [03/May/2022:12:00:47 +0800] "GET /byhsyyGateway/byhsyySystem/verifyCode/getVerifyCode HTTP/1.1" 200 2178 "http://localhost:8881/byhsyyfront/byPages/" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36" "-" "0.037" "0.037"
nginx 的格式对应字段,具体可以在 nginx 配置需要的字段:
$remote_addr 客户端地址
$remote_user 客户端用户名称
$time_local 访问时间和时区
$request 请求的URI和HTTP协议
$status HTTP请求状态
$body_bytes_sent 发送给客户端文件内容大小
$http_referer url跳转来源
$http_user_agent 用户终端浏览器等信息
$http_host 请求地址,即浏览器中你输入的地址(IP或域名)
$request_time 处理请求的总时间,包含了用户数据接收时间
$upstream_response_time 建立连接和从上游服务器接收响应主体的最后一个字节之间的时间
$upstream_connect_time 花费在与上游服务器建立连接上的时间
$upstream_header_time 建立连接和从上游服务器接收响应头的第一个字节之间的时间
找了一份 187 万行的 Nginx 日志,放在 job 目录测试
Doris 建表
在 Doirs 中创建一个 log_text 表
CREATE TABLE test.`log_test` (
`worker_id` VARCHAR ( 250 ) NULL COMMENT "节点ID",
`time_index` VARCHAR ( 250 ) NULL COMMENT "时间索引",
`log_text String NULL COMMENT "log详情"
) ENGINE = OLAP
COMMENT "nginx日志测试"
DISTRIBUTED BY HASH ( `worker_id` ) ;
注意:模型最好是选用 DUPLICATE 表,后面 Nginx 按天分割日志可以根据日期作为 Doirs 表的分区列进行表分区替换,使用 DUPLICATE 表的好处是导入时既不做聚合也不做去重,不用像 UNIQUE 表一样导入还要进行 Compaction,提高性能。
编写 DataX-json 文件
创建一个 datax 的 json 文件,命名为 log_test.json
{
"core": {
"transport": {
"channel": {
"speed": {
}
}
}
},
"job": {
"setting": {
"speed": {
"channel" : 5
}
},
"content": [
{
"reader": {
"name": "txtfilereader",
"parameter": {
"path": ["/app/wwwroot/MBDC/datax/job/access.log"],
"encoding": "UTF-8",
"column": [
{
"index": 0,
"type": "string"
}
],
"fieldDelimiter": "\t"
}
},
"writer": {
"name": "doriswriter",
"parameter": {
"feLoadUrl": ["10.1.1.157:8030"],
"beLoadUrl": ["10.1.1.154:8050","10.1.1.155:8050","10.1.1.156:8050"],
"jdbcUrl": "jdbc:mysql://10.1.1.157:9030",
"database": "test",
"table": "log_test",
"column": ["log_text"],
"username": "root",
"password": "123456",
"postSql": [],
"preSql": [],
"loadProps": {
"max_filter_ratio": "0",
"columns": "worker_id='nginx_01',time_index=str_to_date(regexp_extract(log_text,'\\\\d{2}\/[A-Z][a-z]{2}\/\\\\d{4}:\\\\d{2}:\\\\d{2}:\\\\d{2}',0),'%d/%b/%Y:%H:%i:%s'),log_text"
}
}
}
}
]
}
}
参数解释:
1、core 和 job 参数可根据实际调优,详看 datax 调优;
2、reader 的 path,配置具体 Nginx 的 log 路径。也可以使用 * 通配符替代,如 / nginx/log/access_*,默认会把路径下所有日志给读取,要注意读取的日志的结构必须一致,path 如果配置多个,则 datax 会启动多线程进行读取,后期可以根据这个特性对 Nginx 日志进行更细时间粒度的分割,如按小时、分钟对 Nginx 日志进行分割,再用 datax 多路径多线程去抽取,对日志量大的服务器提高抽取速度,nginx 日志分割配置如下例子:
// 直接在nginx配置文件中修改,即可生产按小时、分钟、秒的粒度日志分割
if ($time_iso8601 ~ "^(\d{4})-(\d{2})-(\d{2})T(\d{2}):(\d{2}):(\d{2})")
{
set $year $1;
set $month $2;
set $day $3;
set $hour $4;
set $minutes $5;
set $seconds $6;
}
access_log /var/logs/xxxx/access/xxxxx_xx_access_$year-$month-$day-hour-minutes-seconds.log main;
3、reader 的 column 我们只写一个列,直接把整行日志信息读取到一个列,原因是 Nginx 的分隔符不好指定,有嵌套空格,如果用户的 app 日志结构化非常清晰,有固定分隔符,可以直接把列序号对应来配置,在分隔符不固定的情况下,可以使用这种方式;
4、reader 的 fieldDelimiter 默认是','逗号,我们替换成制表符 \ t,无需分列;
5、writer 的 column 我们也只定义一个 "log_text",这个必须和 reader 的 column 对应;
6、writer 的 columns 和 column 是不一样的,columns 是 Doris Stream Load 方式的参数,是对应到 Doris 表里的字段,而 columns 是可以使用 Doris 的函数对列进行转换的,利用这个特性,可以在 Stream Load 过程就直接实现对日志进行正则过滤、常量定义、清洗和 where 筛选,非常 NICE!
"columns": "
worker_id='nginx_01',
time_index=str_to_date(regexp_extract(log_text,'\\\\d{2}\/[A-Z][a-z]{2}\/\\\\d{4}:\\\\d{2}:\\\\d{2}:\\\\d{2}',0),'%d/%b/%Y:%H:%i:%s'),
log_text
"
worker_id 我这里直接等于一个常量,用户其实可以根据 etl 脚本进行动态传参,方便识别日志是哪一台 Nginx 节点。
time_index 字段我利用正则函数 + str_to_date() 函数抽取 Nginx 日志里的日志时间,方便 Doris 表可以利用这个时间字段进行动态分区,这里注意 \ d 在 json 文件里需加上转义符 \d。
log_text 则是我 reader 和 writer 定义的列;
7、max_filter_ratio,Doirs 写入记录的错误容忍比率,0 代表容忍 0 错误率,0.2 代表允许容忍 20% 的错误率。
导入 Doirs
在 Datax 的目录对已创建好的 json 文件执行导入命令:
./bin/datax.py --jvm="-Xms3G -Xmx3G -XX:-UseGCOverheadLimit" ./job/log_test.json

可以看到 187 万行的日志在单机和没调优的情况下花费 1 分钟的样子,jvm 参数根据实际情况调整,默认是 1G,如果不够会报 OOM,详细参数参考 Datax 官网。
Doris 表数据已经进来: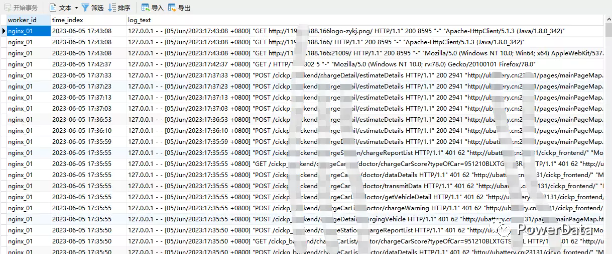
对数据行数验证:

数量一致。因为设置 max_filter_ratio=0,写入错误 Doris 会同步返回错误信息 url 进行修改。
日志检索
测试服务器情况: 1FE 3BE 8C16G
Doris 给日志表创建倒排索引
CREATE INDEX log_text ON test.log_test(log_text) USING INVERTED PROPERTIES("parser" = "english");

需求 1,查询日志出现 "POST" 关键字的次数,用 like 方式:
SELECT count(1) FROM test.log_test WHERE log_text like '%POST%';

需求 2,查询接口被访问次数,使用 MATCH_ALL 和 MATCH_ANY 关键字:
SELECT count(1) FROM test.log_test WHERE log_text MATCH_ANY '/estimateDetails';
SELECT count(1) FROM test.log_test WHERE log_text MATCH_ALL '/estimateDetails /dataDetails';

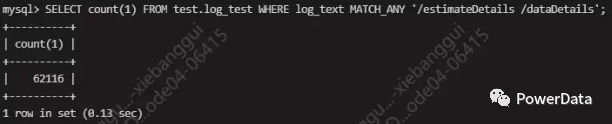
需求 3,查询失败次数
SELECT count(1) FROM test.log_test WHERE log_text MATCH_ALL '401';

需求 4,系统类型
SELECT count(1) FROM test.log_test WHERE log_text not like '%Win64%';

补充
另外,Apache Doris 也可以使用 Json 格式文本进行 Stream Load 导入,2.0 还实现了动态表的 Json 格式进行传输,这里 Datax 我还没想好怎么适配动态 Json 传输到 Doris 里,理论上是把 Json 格式的文本日志每一行 Json 存进一个列,在 Doris writer 的 loadProps 里指定 format:json 参数就可以了,有空的朋友可以试试这一种方式。
动态 Schema 表(实验性功能)
自动推断半结构化 JSON 数据的字段名称和类型
根据写入的数据动态拓展相应数据表的 Schema。
参考:https://doris.apache.org/docs/dev/data-table/dynamic-schema-table
总结
谈谈 Datax,对日志进行采集为什么我不是选用 ELK、Flume 和 Loki+Grafana 等高可用和分布式的组件,一是 Doirs 在日志方面的外部生态拓展就 DataX doriswriter 和 Filebeat+Logstash Doris Output Plugin,除了 Filebeat+Logstash,我选我们这边常用的导数工具 Datax 了,二是 ELK 和 Flume 等组件对于我们公司埋点数据量来说太重了,需自己实现 Http 方式 Sink 到 Doris 进行调试,我们尽量秉承如无必要勿增实体原则,聚焦于效率使用现成组件。
DataX 一个非常好的地方就是 "开箱即用",编译完直接用,用完就关闭的特点,单机多线程批采集千万行日志,性能也非常不错,缺点就是不能断点续传和内存优化不够容易 OOM,这个就需要人工进行调优了,Datax 可以对节点资源进行参数控制,比单纯使用 Http Strean load 的方式更加容易性能管理,不管是 DataX 还是 Http,本质还是使用了 Doris 的 Strean load 方式实现,批存批导还能使用 sql 函数对列进行过滤和筛选,配合日志文件按时间间隔裁剪 + Doris 时间分区建表,可以微批对业务埋点日志进行 ETL 管理。
而不规则类型的日志的采集,DataX 和 Http Strean load 方式都不适合,比如监控组件日志,通常 ERROR 时会带 java 堆栈信息的。

这种不规则的日志类型更适合用 Filebeat+Logstash Doris Output Plugin 更丰富的正则计算前后记录的方式进行采集,还有云场景和千亿级日志等场景,最好优选 Flume 等更加高可用的日志采集方式,这就大家在架构之间衡量做选择。
谈谈 Apache Doris,Doris 2.0 除了很多激动人心的功能就不细说了,可以去官网下载进行体验,在日志检索方面,未来配合监控组件可以在日志场景中大有可为,本次测试数据量 200W 左右远远达不到测试要求,只是体验一下功能和提供给日志量中等的公司一种简单的日志 ETL 链路,Doris 内部测试亿级日志场景一样性能非常好。
想要加入社区或对本文有任何疑问,可直接添加作者微信交流。
 图:作者微信
图:作者微信
我们是由一群数据从业人员,因为热爱凝聚在一起,以开源精神为基础,组成的 PowerData 数据之力社区。
可关注下方公众号后点击 “加入我们”,与 PowerData 一起成长。