【实战】CDH6.3.0 集成 Atlas2.1.0 部署及使用
本文由 PowerData 王昱翔贡献
姓名:王昱翔
花名:醉舞斜陽
微信:ycwziyan
年龄:85 后
工作经验:10 年以上
工作内容:运维,架构,数仓,数开
自我介绍:家穷人丑,一米八九,小学文化,农村户口,今来社区,紧跟大佬,苦练技术。
全文共 5009 个字,建议阅读 35 分钟
1 Atlas 是什么?
2 Atlas 架构原理
3 Atlas 安装及使用
(1) 下载源码包 2.1.0,IDEA 打开
(2) 修改相关版本与 CDH 版本对应
(3) 兼容 Hive2.1.1 需要修改的代码
(4) 编译
(5) 安装
(6) 修改配置文件
(7) 集成 CDH 自带的 Hbase
(8) 集成 Solr
(9) 集成 kafka
(10) 集成 hive
(11) 启动 Atlas
(13) 将 Hive 元数据导入 Atlas
(14) 创建表并插入数据查看数据血缘关系的 demo
(15) 配置列级别的数据血缘
(16) 报错及解决方案如下
1 Atlas 是什么?
Atlas 是一组可扩展和可扩展的核心基础治理服务,使企业能够有效地满足 Hadoop 中的合规性要求,并允许与整个企业数据生态系统集成。Apache Atlas 为组织提供了开放的元数据管理和治理功能,以建立其数据资产的目录,对这些资产进行分类和治理,并为数据科学家,分析师和数据治理团队提供围绕这些数据资产的协作功能。如果没有 Atlas 大数据表依赖问题不好解决,元数据管理需要自行开发,如:hive 血缘依赖图 对于表依赖问题,没有一个可以查询的工具,不方便错误定位,即业务 sql 开发
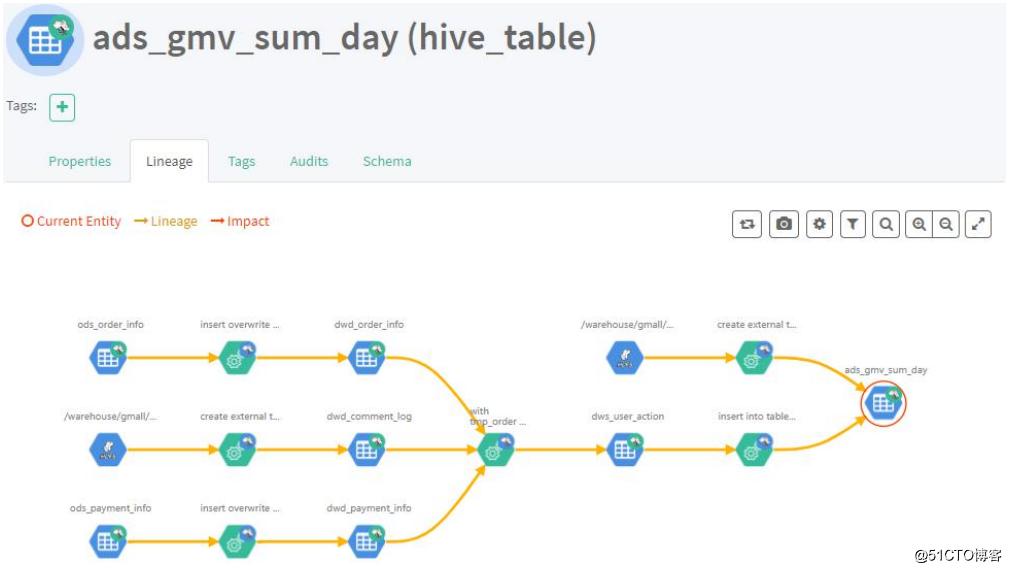 图:表与表之间的血缘依赖
图:表与表之间的血缘依赖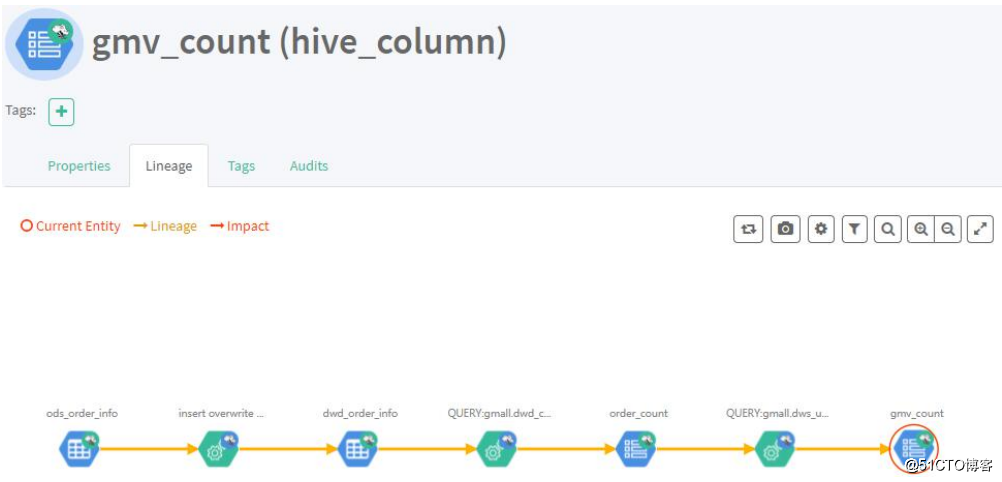 图:字段与字段之间的血缘依赖
图:字段与字段之间的血缘依赖
2 Atlas 架构原理
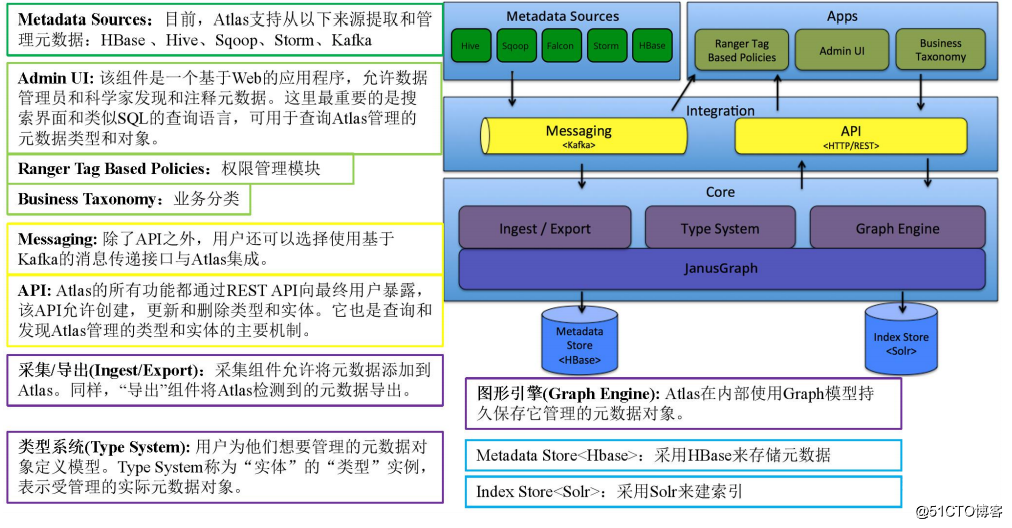 图:Atlas 架构原理
图:Atlas 架构原理
3 Atlas 安装及使用
安装需要组件,HDFS、Yarn、Zookeeper、Kafka、Hbase、Solr、Hive,Python2.7 环境 需要 Maven3.6.3 版本,jdk_180 以上,python2.7,idea 2020.3.2。
(1) 下载源码包 2.1.0,IDEA 打开
因为要与 CDH 集成,修改 pom 文件, 在 repositories 标签中增加 CDH 仓库
<repository>
<id>cloudera</id>
<url>https://repository.cloudera.com/artifactory/cloudera-repos</url>
<releases>
<enabled>true</enabled>
</releases>
<snapshots>
<enabled>false</enabled>
</snapshots>
</repository>
}
(2) 修改相关版本与 CDH 版本对应
<lucene-solr.version>7.4.0</lucene-solr.version>
<hadoop.version>3.0.0-cdh6.3.0</hadoop.version>
<hbase.version>2.1.0-cdh6.3.0</hbase.version>
<solr.version>7.4.0-cdh6.3.0</solr.version>
<hive.version>2.1.1-cdh6.3.0</hive.version>
<kafka.version>2.2.1-cdh6.3.0</kafka.version>
<kafka.scala.binary.version>2.11</kafka.scala.binary.version>
<calcite.version>1.16.0</calcite.version>
<zookeeper.version>3.4.5-cdh6.3.0</zookeeper.version>
<falcon.version>0.8</falcon.version>
<sqoop.version>1.4.7-cdh6.3.0</sqoop.version>
(3) 兼容 Hive2.1.1 需要修改的代码
所需修改的项目位置:apache-atlas-sources-2.1.0\addons\hive-bridge
org/apache/atlas/hive/bridge/HiveMetaStoreBridge.java 577 行
String catalogName = hiveDB.getCatalogName() != null ? hiveDB.getCatalogName().toLowerCase() : null;
修改为
String catalogName = null;
org/apache/atlas/hive/hook/AtlasHiveHookContext.java 81 行
this.metastoreHandler = (listenerEvent != null) ? metastoreEvent.getIHMSHandler() : null;
修改为:
this.metastoreHandler = null;
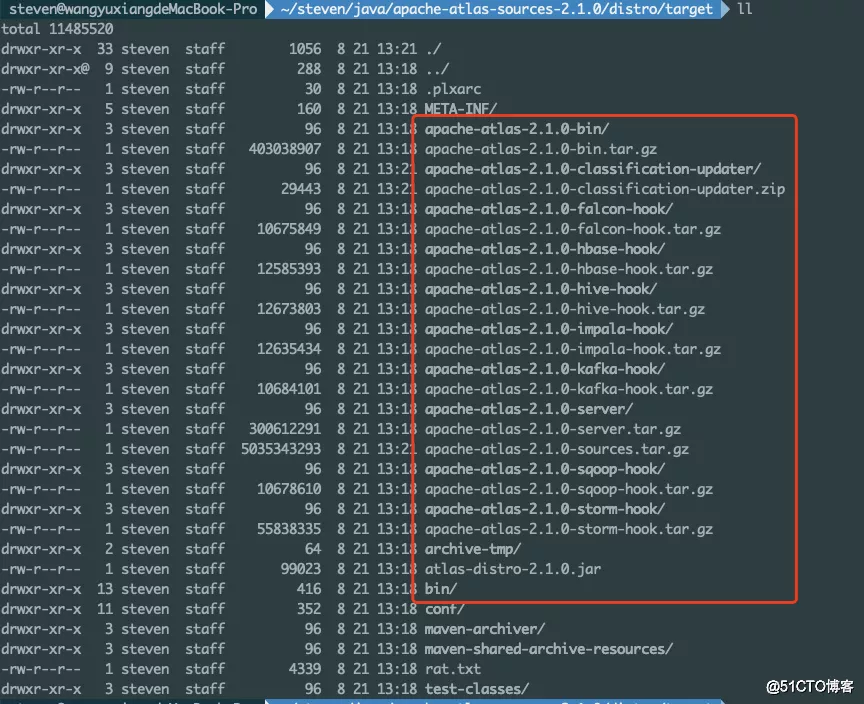
(4) 编译
mvn clean -DskipTests package -Pdist -X -T 8
编译完成的文件在此目录 apache-atlas-sources-2.1.0\distro\target
(5) 安装
mkdir /usr/local/src/atlas
cd /usr/local/src/atlas
#复制apache-atlas-2.1.0-bin.tar.gz到安装目录
tar -zxvf apache-atlas-2.1.0-bin.tar.gz
cd apache-atlas-2.1.0/
(6) 修改配置文件
vim conf\atlas-application.properties
修改以下配置文件
#
# Licensed to the Apache Software Foundation (ASF) under one
# or more contributor license agreements. See the NOTICE file
# distributed with this work for additional information
# regarding copyright ownership. The ASF licenses this file
# to you under the Apache License, Version 2.0 (the
# "License"); you may not use this file except in compliance
# with the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
#
######### Graph Database Configs #########
# Graph Database
#Configures the graph database to use. Defaults to JanusGraph
#atlas.graphdb.backend=org.apache.atlas.repository.graphdb.janus.AtlasJanusGraphDatabase
# Graph Storage
# Set atlas.graph.storage.backend to the correct value for your desired storage
# backend. Possible values:
#
# hbase
# cassandra
# embeddedcassandra - Should only be set by building Atlas with -Pdist,embedded-cassandra-solr
# berkeleyje
#
# See the configuration documentation for more information about configuring the various storage backends.
#
atlas.graph.storage.backend=hbase
atlas.graph.storage.hbase.table=apache_atlas_janus
${graph.storage.properties}
#Hbase
#For standalone mode , specify localhost
#for distributed mode, specify zookeeper quorum here
#atlas.graph.storage.hostname=
#atlas.graph.storage.hbase.regions-per-server=1
#atlas.graph.storage.lock.wait-time=10000
#In order to use Cassandra as a backend, comment out the hbase specific properties above, and uncomment the
#the following properties
#atlas.graph.storage.clustername=
#atlas.graph.storage.port=
# Gremlin Query Optimizer
#
# Enables rewriting gremlin queries to maximize performance. This flag is provided as
# a possible way to work around any defects that are found in the optimizer until they
# are resolved.
#atlas.query.gremlinOptimizerEnabled=true
# Delete handler
#
# This allows the default behavior of doing "soft" deletes to be changed.
#
# Allowed Values:
# org.apache.atlas.repository.store.graph.v1.SoftDeleteHandlerV1 - all deletes are "soft" deletes
# org.apache.atlas.repository.store.graph.v1.HardDeleteHandlerV1 - all deletes are "hard" deletes
#
#atlas.DeleteHandlerV1.impl=org.apache.atlas.repository.store.graph.v1.SoftDeleteHandlerV1
${entity.repository.properties
# Entity audit repository
#
# This allows the default behavior of logging entity changes to hbase to be changed.
#
# Allowed Values:
# org.apache.atlas.repository.audit.HBaseBasedAuditRepository - log entity changes to hbase
# org.apache.atlas.repository.audit.CassandraBasedAuditRepository - log entity changes to cassandra
# org.apache.atlas.repository.audit.NoopEntityAuditRepository - disable the audit repository
#
# atlas.EntityAuditRepository.impl=org.apache.atlas.repository.audit.HBaseBasedAuditRepository
# if Cassandra is used as a backend for audit from the above property, uncomment and set the following
# properties appropriately. If using the embedded cassandra profile, these properties can remain
# commented out.
# atlas.EntityAuditRepository.keyspace=atlas_audit
# atlas.EntityAuditRepository.replicationFactor=1
# Graph Search Index
${graph.index.properties}
atlas.graph.index.search.backend=solr
#Solr
#Solr cloud mode properties
atlas.graph.index.search.solr.mode=cloud
atlas.graph.index.search.solr.zookeeper-url=dbos-bigdata-test003:2181/solr,dbos-bigdata-test005:2181/solr,dbos-bigdata-test004:218/solr
atlas.graph.index.search.solr.zookeeper-connect-timeout=60000
atlas.graph.index.search.solr.zookeeper-session-timeout=60000
#atlas.graph.index.search.solr.wait-searcher=true
#Solr http mode properties
#atlas.graph.index.search.solr.mode=http
#atlas.graph.index.search.solr.http-urls=http://localhost:8983/solr
# ElasticSearch support (Tech Preview)
# Comment out above solr configuration, and uncomment the following two lines. Additionally, make sure the
# hostname field is set to a comma delimited set of elasticsearch master nodes, or an ELB that fronts the masters.
#
# Elasticsearch does not provide authentication out of the box, but does provide an option with the X-Pack product
# https://www.elastic.co/products/x-pack/security
#
# Alternatively, the JanusGraph documentation provides some tips on how to secure Elasticsearch without additional
# plugins: https://docs.janusgraph.org/latest/elasticsearch.html
#atlas.graph.index.search.hostname=localhost
#atlas.graph.index.search.elasticsearch.client-only=true
# Solr-specific configuration property
atlas.graph.index.search.max-result-set-size=150
######### Import Configs #########
#atlas.import.temp.directory=/temp/import
######### Notification Configs #########
atlas.notification.embedded=false
atlas.kafka.data=${sys:atlas.home}/data/kafka
atlas.kafka.zookeeper.connect=dbos-bigdata-test003:2181,dbos-bigdata-test005:2181,dbos-bigdata-test004:2181
atlas.kafka.bootstrap.servers=dbos-bigdata-test003:9092,dbos-bigdata-test004:9092,dbos-bigdata-test005:9092
atlas.kafka.zookeeper.session.timeout.ms=60000
atlas.kafka.zookeeper.connection.timeout.ms=30000
atlas.kafka.zookeeper.sync.time.ms=20
atlas.kafka.auto.commit.interval.ms=1000
atlas.kafka.hook.group.id=atlas
atlas.kafka.enable.auto.commit=false
atlas.kafka.auto.offset.reset=earliest
atlas.kafka.session.timeout.ms=30000
atlas.kafka.offsets.topic.replication.factor=1
atlas.kafka.poll.timeout.ms=1000
atlas.notification.create.topics=true
atlas.notification.replicas=1
atlas.notification.topics=ATLAS_HOOK,ATLAS_ENTITIES
atlas.notification.log.failed.messages=true
atlas.notification.consumer.retry.interval=500
atlas.notification.hook.retry.interval=1000
# Enable for Kerberized Kafka clusters
#atlas.notification.kafka.service.principal=kafka/_HOST@EXAMPLE.COM
#atlas.notification.kafka.keytab.location=/etc/security/keytabs/kafka.service.keytab
## Server port configuration
#atlas.server.http.port=21000
#atlas.server.https.port=21443
######### Security Properties #########
# SSL config
atlas.enableTLS=false
#truststore.file=/path/to/truststore.jks
#cert.stores.credential.provider.path=jceks://file/path/to/credentialstore.jceks
#following only required for 2-way SSL
#keystore.file=/path/to/keystore.jks
# Authentication config
atlas.authentication.method.kerberos=false
atlas.authentication.method.file=true
#### ldap.type= LDAP or AD
atlas.authentication.method.ldap.type=none
#### user credentials file
atlas.authentication.method.file.filename=${sys:atlas.home}/conf/users-credentials.properties
### groups from UGI
#atlas.authentication.method.ldap.ugi-groups=true
######## LDAP properties #########
#atlas.authentication.method.ldap.url=ldap://<ldap server url>:389
#atlas.authentication.method.ldap.userDNpattern=uid={0},ou=People,dc=example,dc=com
#atlas.authentication.method.ldap.groupSearchBase=dc=example,dc=com
#atlas.authentication.method.ldap.groupSearchFilter=(member=uid={0},ou=Users,dc=example,dc=com)
#atlas.authentication.method.ldap.groupRoleAttribute=cn
#atlas.authentication.method.ldap.base.dn=dc=example,dc=com
#atlas.authentication.method.ldap.bind.dn=cn=Manager,dc=example,dc=com
#atlas.authentication.method.ldap.bind.password=<password>
#atlas.authentication.method.ldap.referral=ignore
#atlas.authentication.method.ldap.user.searchfilter=(uid={0})
#atlas.authentication.method.ldap.default.role=<default role>
######### Active directory properties #######
#atlas.authentication.method.ldap.ad.domain=example.com
#atlas.authentication.method.ldap.ad.url=ldap://<AD server url>:389
#atlas.authentication.method.ldap.ad.base.dn=(sAMAccountName={0})
#atlas.authentication.method.ldap.ad.bind.dn=CN=team,CN=Users,DC=example,DC=com
#atlas.authentication.method.ldap.ad.bind.password=<password>
#atlas.authentication.method.ldap.ad.referral=ignore
#atlas.authentication.method.ldap.ad.user.searchfilter=(sAMAccountName={0})
#atlas.authentication.method.ldap.ad.default.role=<default role>
######### JAAS Configuration ########
#atlas.jaas.KafkaClient.loginModuleName = com.sun.security.auth.module.Krb5LoginModule
#atlas.jaas.KafkaClient.loginModuleControlFlag = required
#atlas.jaas.KafkaClient.option.useKeyTab = true
#atlas.jaas.KafkaClient.option.storeKey = true
#atlas.jaas.KafkaClient.option.serviceName = kafka
#atlas.jaas.KafkaClient.option.keyTab = /etc/security/keytabs/atlas.service.keytab
#atlas.jaas.KafkaClient.option.principal = atlas/_HOST@EXAMPLE.COM
######### Server Properties #########
atlas.rest.address=http://localhost:21000
# If enabled and set to true, this will run setup steps when the server starts
atlas.server.run.setup.on.start=false
######### Entity Audit Configs #########
atlas.audit.hbase.tablename=apache_atlas_entity_audit
atlas.audit.zookeeper.session.timeout.ms=1000
atlas.audit.hbase.zookeeper.quorum=dbos-bigdata-test003:2181,dbos-bigdata-test005:2181,dbos-bigdata-test004:2181
# Hive
atlas.hook.hive.synchronous=false
atlas.hook.hive.numRetries=3
atlas.hook.hive.queueSize=10000
atlas.cluster.name=primary
######### High Availability Configuration ########
atlas.server.ha.enabled=false
#### Enabled the configs below as per need if HA is enabled #####
#atlas.server.ids=id1
#atlas.server.address.id1=localhost:21000
#atlas.server.ha.zookeeper.connect=localhost:2181
#atlas.server.ha.zookeeper.retry.sleeptime.ms=1000
#atlas.server.ha.zookeeper.num.retries=3
#atlas.server.ha.zookeeper.session.timeout.ms=20000
## if ACLs need to be set on the created nodes, uncomment these lines and set the values ##
#atlas.server.ha.zookeeper.acl=<scheme>:<id>
#atlas.server.ha.zookeeper.auth=<scheme>:<authinfo>
######### Atlas Authorization #########
atlas.authorizer.impl=simple
atlas.authorizer.simple.authz.policy.file=atlas-simple-authz-policy.json
######### Type Cache Implementation ########
# A type cache class which implements
# org.apache.atlas.typesystem.types.cache.TypeCache.
# The default implementation is org.apache.atlas.typesystem.types.cache.DefaultTypeCache which is a local in-memory type cache.
#atlas.TypeCache.impl=
######### Performance Configs #########
#atlas.graph.storage.lock.retries=10
#atlas.graph.storage.cache.db-cache-time=120000
######### CSRF Configs #########
atlas.rest-csrf.enabled=true
atlas.rest-csrf.browser-useragents-regex=^Mozilla.*,^Opera.*,^Chrome.*
atlas.rest-csrf.methods-to-ignore=GET,OPTIONS,HEAD,TRACE
atlas.rest-csrf.custom-header=X-XSRF-HEADER
############ KNOX Configs ################
#atlas.sso.knox.browser.useragent=Mozilla,Chrome,Opera
#atlas.sso.knox.enabled=true
#atlas.sso.knox.providerurl=https://<knox gateway ip>:8443/gateway/knoxsso/api/v1/websso
#atlas.sso.knox.publicKey=
############ Atlas Metric/Stats configs ################
# Format: atlas.metric.query.<key>.<name>
atlas.metric.query.cache.ttlInSecs=900
#atlas.metric.query.general.typeCount=
#atlas.metric.query.general.typeUnusedCount=
#atlas.metric.query.general.entityCount=
#atlas.metric.query.general.tagCount=
#atlas.metric.query.general.entityDeleted=
#
#atlas.metric.query.entity.typeEntities=
#atlas.metric.query.entity.entityTagged=
#
#atlas.metric.query.tags.entityTags=
######### Compiled Query Cache Configuration #########
# The size of the compiled query cache. Older queries will be evicted from the cache
# when we reach the capacity.
#atlas.CompiledQueryCache.capacity=1000
# Allows notifications when items are evicted from the compiled query
# cache because it has become full. A warning will be issued when
# the specified number of evictions have occurred. If the eviction
# warning threshold <= 0, no eviction warnings will be issued.
#atlas.CompiledQueryCache.evictionWarningThrottle=0
######### Full Text Search Configuration #########
#Set to false to disable full text search.
#atlas.search.fulltext.enable=true
######### Gremlin Search Configuration #########
#Set to false to disable gremlin search.
atlas.search.gremlin.enable=false
########## Add http headers ###########
#atlas.headers.Access-Control-Allow-Origin=*
#atlas.headers.Access-Control-Allow-Methods=GET,OPTIONS,HEAD,PUT,POST
#atlas.headers.<headerName>=<headerValue>
######### UI Configuration ########
atlas.ui.default.version=v1
atlas.hook.sqoop.synchronous=false
atlas.hook.sqoop.numRetries=3
atlas.hook.sqoop.queueSize=10000
atlas.kafka.metric.reporters=org.apache.kafka.common.metrics.JmxReporter
atlas.kafka.client.id=sqoop-atlas
vim conf/atlas-env.sh
#!/usr/bin/env bash
#
# Licensed to the Apache Software Foundation (ASF) under one
# or more contributor license agreements. See the NOTICE file
# distributed with this work for additional information
# regarding copyright ownership. The ASF licenses this file
# to you under the Apache License, Version 2.0 (the
# "License"); you may not use this file except in compliance
# with the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
#
# The java implementation to use. If JAVA_HOME is not found we expect java and jar to be in path
#export JAVA_HOME=
# any additional java opts you want to set. This will apply to both client and server operations
#export ATLAS_OPTS=
# any additional java opts that you want to set for client only
#export ATLAS_CLIENT_OPTS=
# java heap size we want to set for the client. Default is 1024MB
#export ATLAS_CLIENT_HEAP=
# any additional opts you want to set for atlas service.
#export ATLAS_SERVER_OPTS=
# indicative values for large number of metadata entities (equal or more than 10,000s)
#export ATLAS_SERVER_OPTS="-server -XX:SoftRefLRUPolicyMSPerMB=0 -XX:+CMSClassUnloadingEnabled -XX:+UseConcMarkSweepGC -XX:+CMSParallelRemarkEnabled -XX:+PrintTenuringDistribution -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=dumps/atlas_server.hprof -Xloggc:logs/gc-worker.log -verbose:gc -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=10 -XX:GCLogFileSize=1m -XX:+PrintGCDetails -XX:+PrintHeapAtGC -XX:+PrintGCTimeStamps"
# java heap size we want to set for the atlas server. Default is 1024MB
#export ATLAS_SERVER_HEAP=
# indicative values for large number of metadata entities (equal or more than 10,000s) for JDK 8
#export ATLAS_SERVER_HEAP="-Xms15360m -Xmx15360m -XX:MaxNewSize=5120m -XX:MetaspaceSize=100M -XX:MaxMetaspaceSize=512m"
# What is is considered as atlas home dir. Default is the base locaion of the installed software
#export ATLAS_HOME_DIR=
# Where log files are stored. Defatult is logs directory under the base install location
#export ATLAS_LOG_DIR=
# Where pid files are stored. Defatult is logs directory under the base install location
#export ATLAS_PID_DIR=
# where the atlas titan db data is stored. Defatult is logs/data directory under the base install location
#export ATLAS_DATA_DIR=
# Where do you want to expand the war file. By Default it is in /server/webapp dir under the base install dir.
#export ATLAS_EXPANDED_WEBAPP_DIR=
export HBASE_CONF_DIR=/etc/hbase/conf
export ATLAS_SERVER_HEAP="-Xms15360m -Xmx15360m -XX:MaxNewSize=5120m -XX:MetaspaceSize=100M -XX:MaxMetaspaceSize=512m"
export ATLAS_SERVER_OPTS="-server -XX:SoftRefLRUPolicyMSPerMB=0 -XX:+CMSClassUnloadingEnabled -XX:+UseConcMarkSweepGC -XX:+CMSParallelRemarkEnabled -XX:+PrintTenuringDistribution -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=dumps/atlas_server.hprof -Xloggc:logs/gc-worker.log -verbose:gc -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=10 -XX:GCLogFileSize=1m -XX:+PrintGCDetails -XX:+PrintHeapAtGC -XX:+PrintGCTimeStamps"
# indicates whether or not a local instance of HBase should be started for Atlas
export MANAGE_LOCAL_HBASE=false
# indicates whether or not a local instance of Solr should be started for Atlas
export MANAGE_LOCAL_SOLR=false
# indicates whether or not cassandra is the embedded backend for Atlas
export MANAGE_EMBEDDED_CASSANDRA=false
# indicates whether or not a local instance of Elasticsearch should be started for Atlas
export MANAGE_LOCAL_ELASTICSEARCH=false
vim conf/atlas-log4j.xml
修改日志的配置文件
#去掉如下代码的注释(开启如下代码)
<appender >
<param ${atlas.log.dir}/atlas_perf.log" />
<param />
<param />
<layout class="org.apache.log4j.PatternLayout">
<param %d|%t|%m%n" />
</layout>
</appender>
<logger >
<level value="debug" />
<appender-ref ref="perf_appender" />
</logger>
(7) 集成 CDH 自带的 Hbase
添加 hbase 集群配置文件到 apache-atlas-2.1.0/conf/hbase 下 (这里连接的路径需要和上面 atlas-env.sh 配置中一样)
ln -s /etc/hbase/conf/ /usr/local/src/atlas/apache-atlas-2.1.0/conf/hbase/
(8) 集成 Solr
将 apache-atlas-2.1.0/conf/solr 文件拷贝到 solr 所有节点的安装目录下,更名为 atlas-solr
scp -r /usr/local/src/atlas/apache-atlas-2.1.0/conf/solr root@dbos-bigdata-test002:/opt/cloudera/parcels/CDH-6.3.0-1.cdh6.3.0.p0.1279813/lib/solr/
scp -r /usr/local/src/atlas/apache-atlas-2.1.0/conf/solr root@dbos-bigdata-test003:/opt/cloudera/parcels/CDH-6.3.0-1.cdh6.3.0.p0.1279813/lib/solr/
scp -r /usr/local/src/atlas/apache-atlas-2.1.0/conf/solr root@dbos-bigdata-test004:/opt/cloudera/parcels/CDH-6.3.0-1.cdh6.3.0.p0.1279813/lib/solr/
#在solr节点
cd /opt/cloudera/parcels/CDH-6.3.0-1.cdh6.3.0.p0.1279813/lib/solr/
mv solr/ atlas-solr 注意:三个solr节点都要修改
#在任意solr节点修改solr对应的bash
vim /etc/passwd
/sbin/nologin 修改为 /bin/bash
#切换solr用户执行
su solr
/opt/cloudera/parcels/CDH-6.3.0-1.cdh6.3.0.p0.1279813/lib/solr/bin/solr create -c vertex_index -d /opt/cloudera/parcels/CDH-6.3.0-1.cdh6.3.0.p0.1279813/lib/solr/atlas-solr -shards 3 -replicationFactor 2
/opt/cloudera/parcels/CDH-6.3.0-1.cdh6.3.0.p0.1279813/lib/solr/bin/solr create -c edge_index -d /opt/cloudera/parcels/CDH-6.3.0-1.cdh6.3.0.p0.1279813/lib/solr/atlas-solr -shards 3 -replicationFactor 2
/opt/cloudera/parcels/CDH-6.3.0-1.cdh6.3.0.p0.1279813/lib/solr/bin/solr create -c fulltext_index -d /opt/cloudera/parcels/CDH-6.3.0-1.cdh6.3.0.p0.1279813/lib/solr/atlas-solr -shards 3 -replicationFactor 2
#如果创建错误,可使用 /opt/cloudera/parcels/CDH/lib/solr/bin/solr delete -c ${collection_name} 删除
#切换root用户继续配置其他
su root
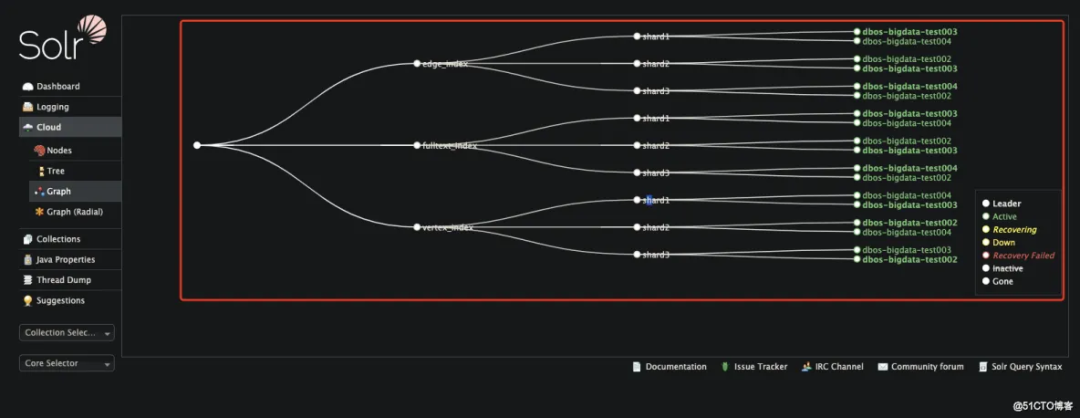
solr web 控制台: http://dbos-bigdata-test002:8983/solr/#/~cloud 验证是否启动成功
(9) 集成 kafka
创建 kafka-topic
kafka-topics --zookeeper dbos-bigdata-test003:2181,dbos-bigdata-test005:2181,dbos-bigdata-test004:2181/kafka --create --replication-factor 3 --partitions 3 --topic _HOATLASOK
kafka-topics --zookeeper dbos-bigdata-test003:2181,dbos-bigdata-test005:2181,dbos-bigdata-test004:2181/kafka --create --replication-factor 3 --partitions 3 --topic ATLAS_ENTITIES
kafka-topics --zookeeper dbos-bigdata-test003:2181,dbos-bigdata-test005:2181,dbos-bigdata-test004:2181/kafka --create --replication-factor 3 --partitions 3 --topic ATLAS_HOOK
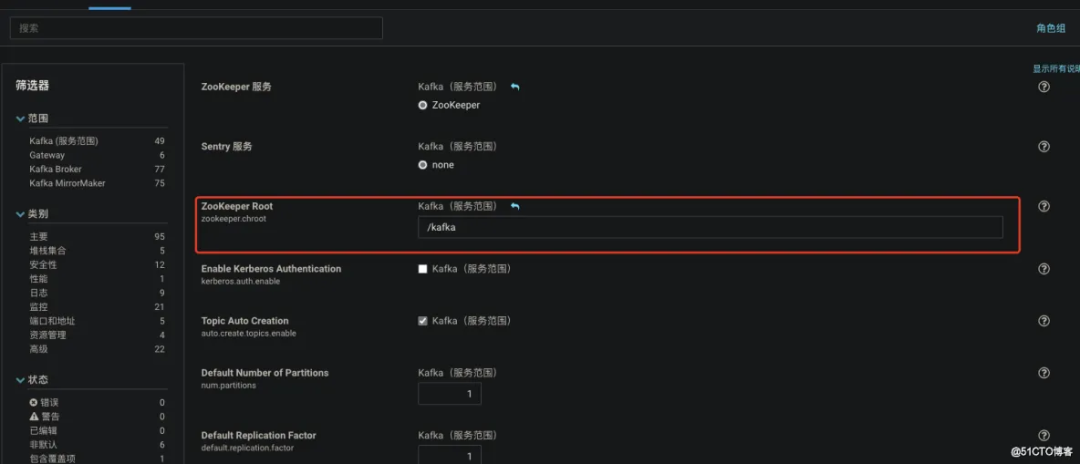
注意:
在最后的 zookeeper 主机的后面要加上 / kafka,不然 toppic 创建不成功, 原因是 CDH6.3.0 默认配置的 zookepper root 的 kafka 加了 / kafka
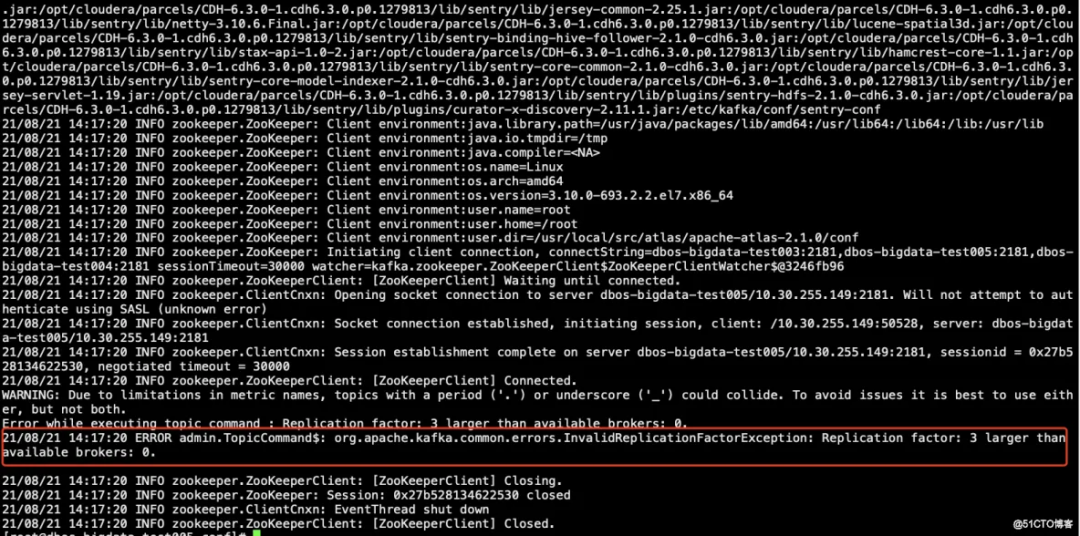 查看 kafka 是否创建成功
查看 kafka 是否创建成功
kafka-topics --list --zookeeper dbos-bigdata-test003:2181,dbos-bigdata-test005:2181,dbos-bigdata-test004:2181/kafka
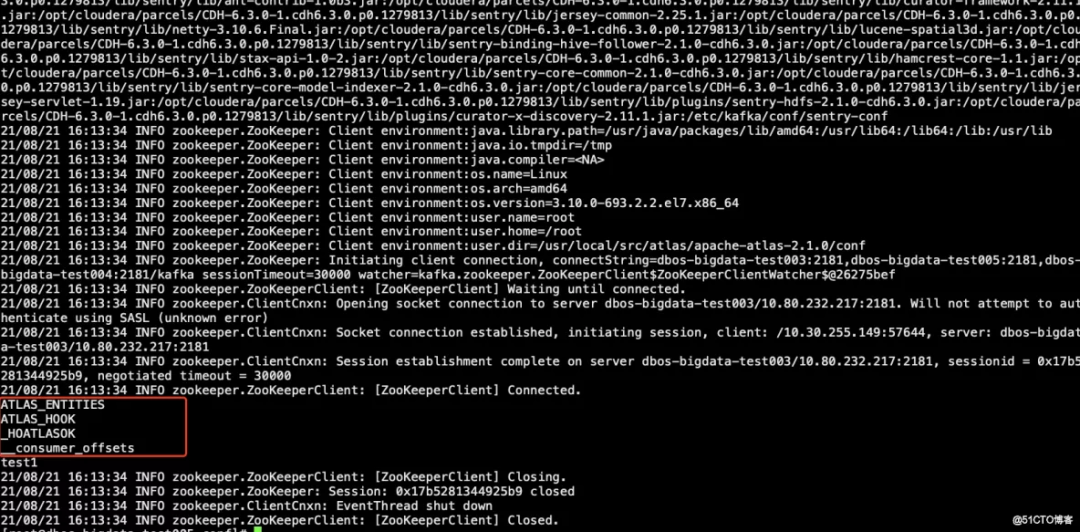
(10) 集成 hive
将 atlas-application.properties 配置文件,压缩加入到 atlas-plugin-classloader-2.0.0.jar 中
#必须在此路径打包,才能打到第一级目录下
cd /usr/local/src/atlas/apache-atlas-2.1.0/conf
zip -u /usr/local/src/atlas/apache-atlas-2.1.0/hook/hive/atlas-plugin-classloader-2.1.0.jar atlas-application.properties
修改 hive-site.xml
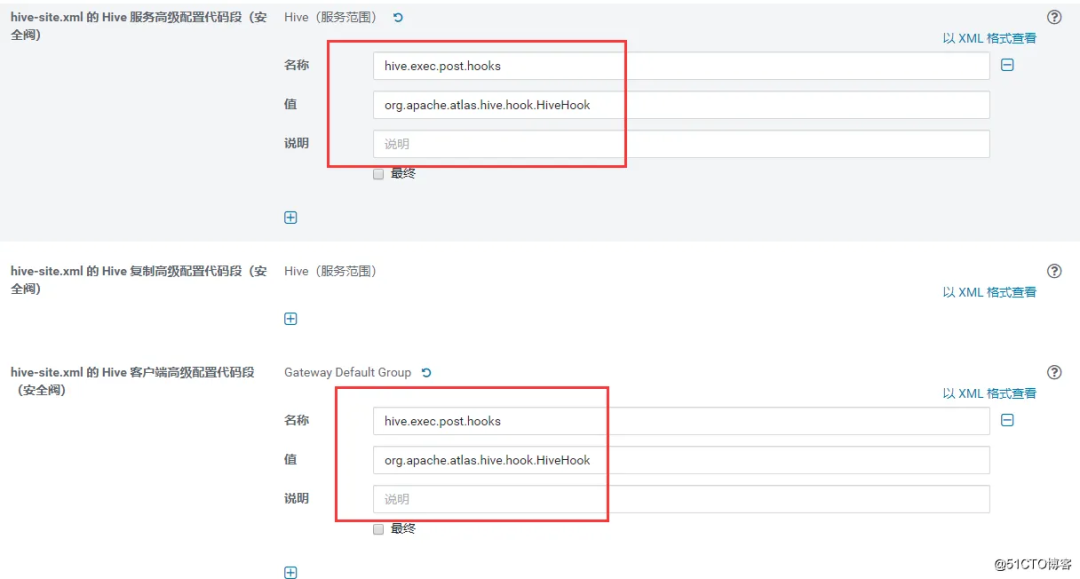
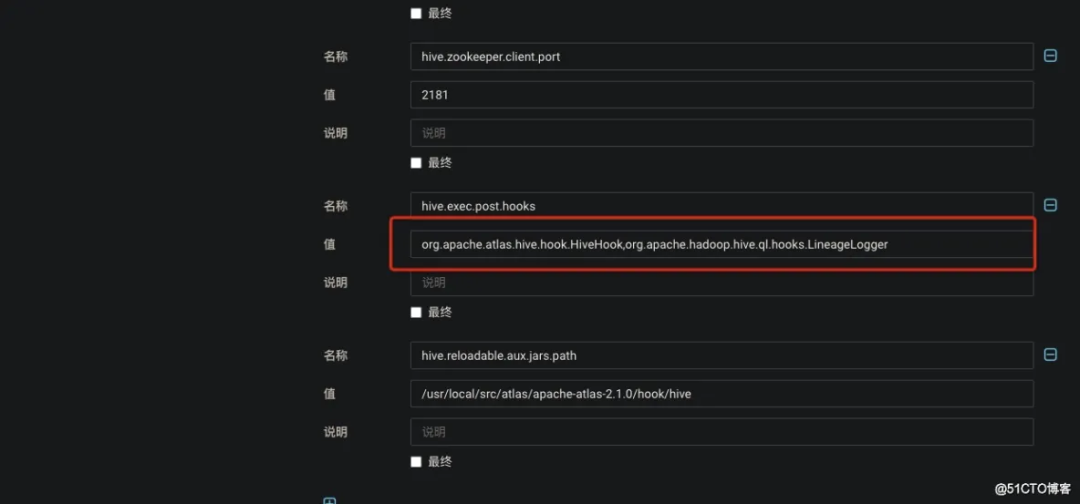
<property>
<name>hive.exec.post.hooks</name>
<value>org.apache.atlas.hive.hook.HiveHook</value>
</property>
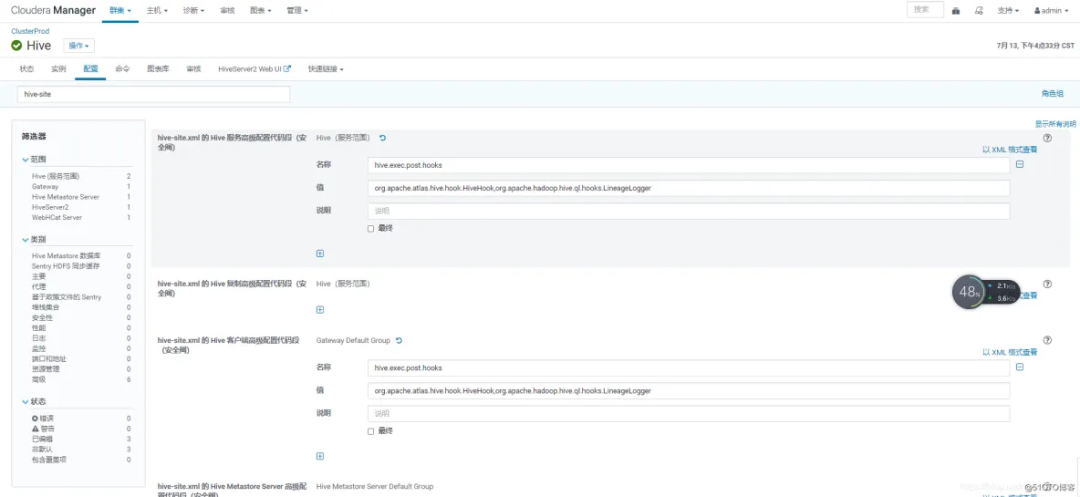
修改 hive-env.sh 的 Gateway 客户端环境高级配置代码段(安全阀)
修改 Hive 的 jar 的辅助目录
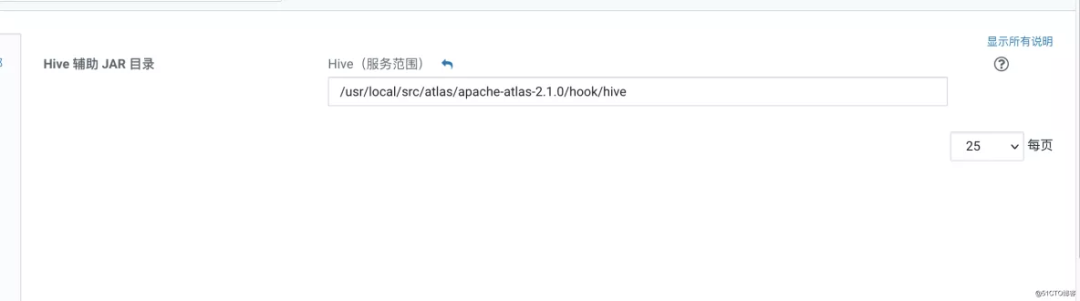
修改 hive-site.xml 的 HiveServer2 高级配置代码段(安全阀)

<property>
<name>hive.exec.post.hooks</name>
<value>org.apache.atlas.hive.hook.HiveHook</value>
</property>
<property>
<name>hive.reloadable.aux.jars.path</name>
<value>/usr/local/src/atlas/apache-atlas-2.1.0/hook/hive</value>
</property>
修改 HiveServer2 环境高级配置代码段
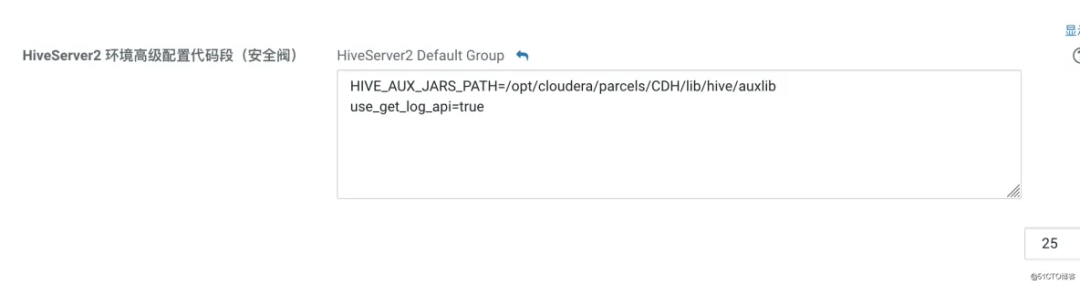
HIVE_AUX_JARS_PATH=/usr/local/src/atlas/apache-atlas-2.1.0/hook/hive
原来我配置的是以上的配置,后来发现 hue 无法连接后台,报错。
后来在网上查我又改成以下的配置
HIVE_AUX_JARS_PATH=/opt/cloudera/parcels/CDH/lib/hive/auxlib
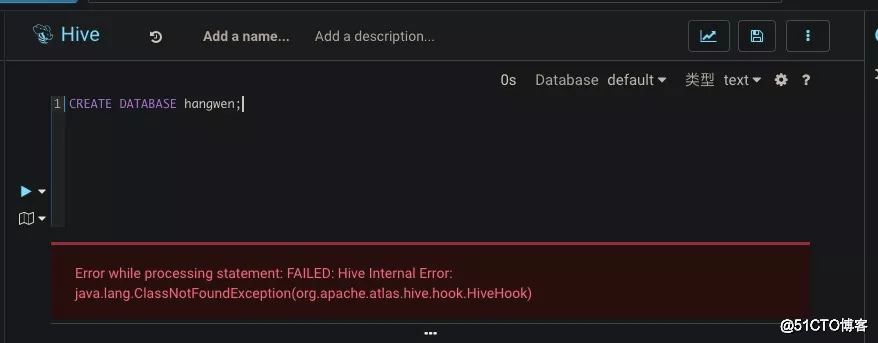 以上是报错。
以上是报错。
将配置好的 Atlas 包发往各个 hive 节点后重启集群
scp -P65322 -r /usr/local/src/atlas/apache-atlas-2.1.0 root@dbos-bigdata-test002:/usr/local/src/atlas/
scp -P65322 -r /usr/local/src/atlas/apache-atlas-2.1.0 root@dbos-bigdata-test003:/usr/local/src/atlas/
scp -P65322 -r /usr/local/src/atlas/apache-atlas-2.1.0 root@dbos-bigdata-test004:/usr/local/src/atlas/
更新后并重启集群的配置并分发客户端到各个节点
将 atlas 配置文件 copy 到 / etc/hive/conf 下 (集群各个节点)
scp /usr/local/src/atlas/apache-atlas-2.1.0/conf/atlas-application.properties root@dbos-bigdata-test002:/etc/hive/conf
scp /usr/local/src/atlas/apache-atlas-2.1.0/conf/atlas-application.properties root@dbos-bigdata-test003:/etc/hive/conf
scp /usr/local/src/atlas/apache-atlas-2.1.0/conf/atlas-application.properties root@dbos-bigdata-test004:/etc/hive/conf
(11) 启动 Atlas
cd /usr/local/src/atlas/apache-atlas-2.1.0/
#启动
./bin/atlas_start.py
#停止:
./bin/atlas_stop.py

注意监控日志,查看是否有报错。主要是看 application.log

(13) 将 Hive 元数据导入 Atlas
atlas 添加 hive 的环境变量
vim /etc/profile
#>>>
#hive
export HIVE_HOME=/opt/cloudera/parcels/CDH-6.3.0-1.cdh6.3.0.p0.1279813/lib/hive
export HIVE_CONF_DIR=/etc/hive/conf
export PATH=$HIVE_HOME/bin:$PATH
#<<<
source /etc/profile
我的最终的profile的配置是:
#set default jdk1.8 env
export JAVA_HOME=/usr/java/jdk1.8.0_181-cloudera
export JRE_HOME=/usr/java/jdk1.8.0_181-cloudera/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export HADOOP_CONF_DIR=/etc/hadoop/conf
export HADOOP_CLASSPATH=`hadoop classpath`
export HBASE_CONF_DIR=/etc/hbase/conf
export FLINK_HOME=/opt/flink
export HIVE_HOME=/opt/cloudera/parcels/CDH-6.3.0-1.cdh6.3.0.p0.1279813/lib/hive
export HIVE_CONF_DIR=/etc/hive/conf
export M2_HOME=/usr/local/maven/apache-maven-3.5.4
export PATH=${JAVA_HOME}/bin:${JRE_HOME}/bin:${FLINK_HOME}/bin:${M2_HOME}/bin:${HIVE_HOME}/bin:$PATH
执行 atlas 脚本
./bin/import-hive.sh
#输入用户名:admin;输入密码:admin(如修改请使用修改的)
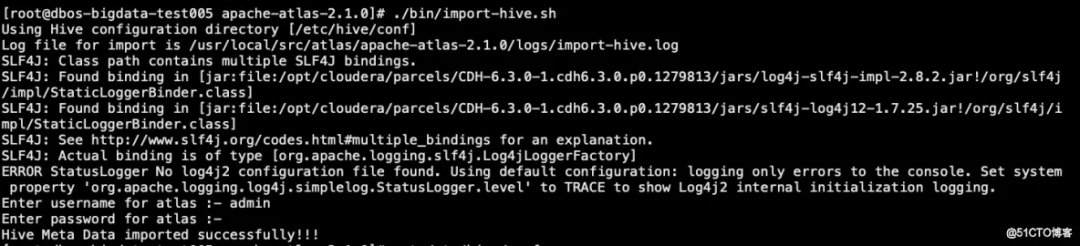 以上提示导入成功
以上提示导入成功
(14) 创建表并插入数据查看数据血缘关系的 demo
CREATE TABLE t_ppp (
id int ,
pice decimal(2, 1)
) ;
insert into t_ppp values (1,2.2);
CREATE TABLE t_ppp_bak (
id int ,
pice decimal(2, 1)
) ;
insert overwrite table t_ppp_bak select id,pice from t_ppp;
CREATE VIEW IF NOT EXISTS t_ppp_view AS SELECT id,pice FROM t_ppp_bak;
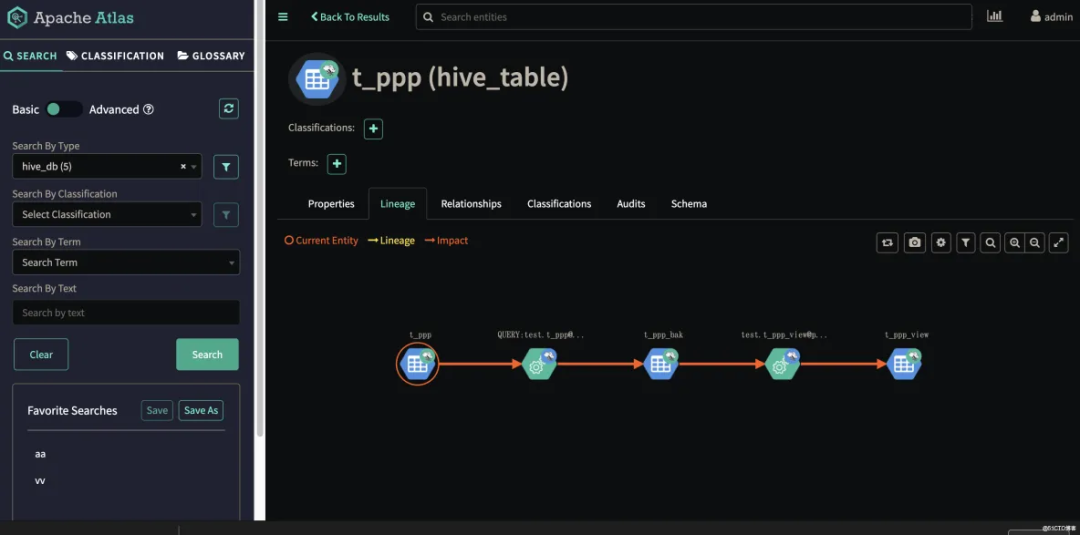
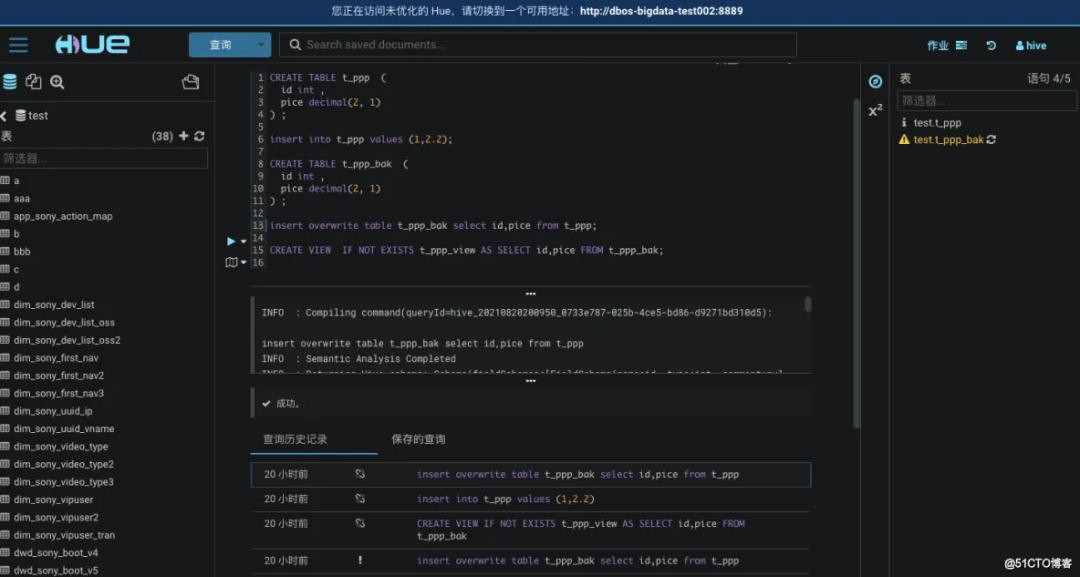 以下是数据血缘关系的地图。
以下是数据血缘关系的地图。
(15) 配置列级别的数据血缘
hive 配置的地方,用逗号隔开,增加列级别配置,如下:
org.apache.hadoop.hive.ql.hooks.LineageLogger
 hive-site.xml 的 HiveServer2 高级配置代码段
hive-site.xml 的 HiveServer2 高级配置代码段
配置完后重启 hive 服务后即可。
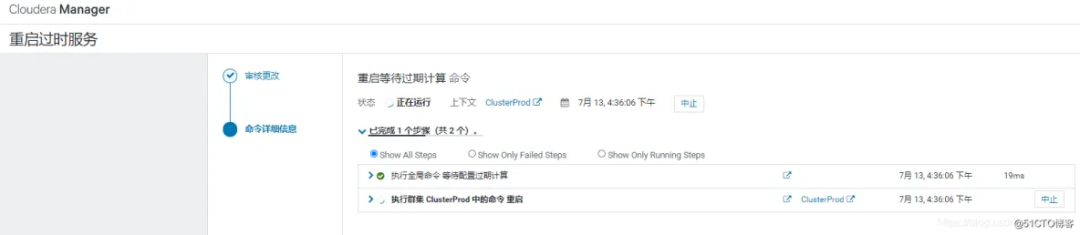
重新执行 hive 的插入语句
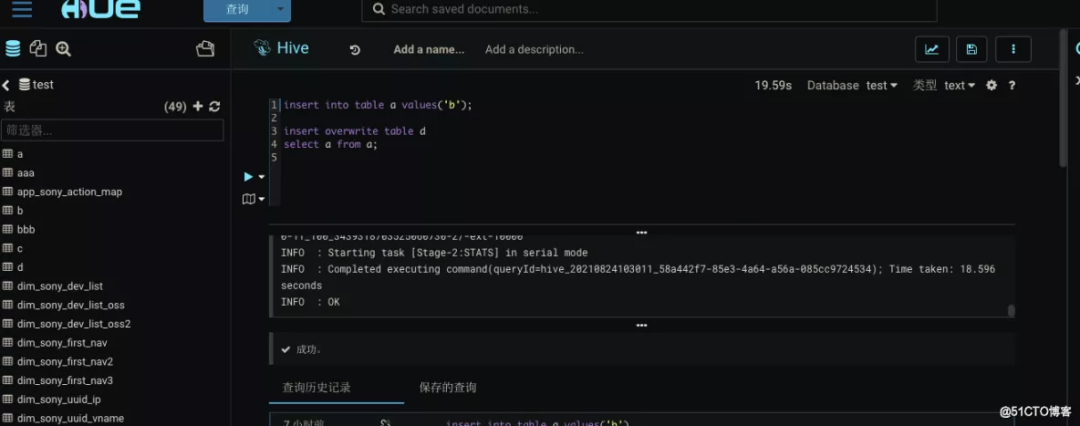 字段之间的血缘关系展示如下:
字段之间的血缘关系展示如下:

(16) 报错及解决方案如下
报错 1: 导入 hive 元数据报少包
[root@dbos-bigdata-test005 apache-atlas-2.1.0]# ./bin/import-hive.sh
Using Hive configuration directory [/etc/hive/conf/conf]
Log file for import is /usr/local/src/atlas/apache-atlas-2.1.0/logs/import-hive.log
Error: A JNI error has occurred, please check your installation and try again
Exception in thread "main" java.lang.NoClassDefFoundError: org/apache/hadoop/hive/ql/metadata/Hive
at java.lang.Class.getDeclaredMethods0(Native Method)
at java.lang.Class.privateGetDeclaredMethods(Class.java:2701)
at java.lang.Class.privateGetMethodRecursive(Class.java:3048)
at java.lang.Class.getMethod0(Class.java:3018)
at java.lang.Class.getMethod(Class.java:1784)
at sun.launcher.LauncherHelper.validateMainClass(LauncherHelper.java:544)
at sun.launcher.LauncherHelper.checkAndLoadMain(LauncherHelper.java:526)
Caused by: java.lang.ClassNotFoundException: org.apache.hadoop.hive.ql.metadata.Hive
at java.net.URLClassLoader.findClass(URLClassLoader.java:381)
解决方案:
cp /opt/cloudera/parcels/CDH/lib/hive/lib/hive-exec-2.1.1-cdh6.3.0.jar /usr/local/src/atlas/apache-atlas-2.1.0/hook/hive/atlas-hive-plugin-impl
cd /usr/local/src/atlas/apache-atlas-2.1.0/hook/hive/
mv atlas-hive-plugin-impl/* ./
rm -rf hive-bridge-shim-2.1.0.jar
cp /opt/cloudera/parcels/CDH/lib/hive/lib/hive-exec-2.1.1-cdh6.3.0.jar /usr/local/src/atlas/apache-atlas-2.1.0/hook/hive/
报错 2: root 用户找不到 HIVE_HOME Please set HIVE_HOME to the root of Hive installation
解决方案: 在 profile 设置 HIVE_HOME 环境变量
想要加入社区或对本文有任何疑问,可直接添加作者微信交流。