【技术分享】元数据与数据血缘实现思路
本文由 PowerData 灵魂人物贡献
姓名:李奇峰
花名:灵魂人物
微信:bigdata_qifeng
年龄:95 后
工作经验:3-5 年
工作内容:数仓, 数开, 数据中台, 后端开发
自我介绍:一个对数据中台非常感兴趣的人
全文共 7013 个字,建议阅读 15 分钟
目前数据资产热度飙升,元数据与数据血缘成为了很多公司开展数据管理工作的重要抓手,通过元数据对数据信息进行有效管理,通过数据血缘梳理数据关系。
各位数开和数仓小伙伴,对于元数据和数据血缘的技术实现可能并不清晰,此篇文章会概括性的和大家介绍元数据与血缘的技术实现思路,让大家能有一个较为清晰的认知开展对应的开发工作。
技术分享 - 活动预告

概念介绍
元数据
描述数据的数据,本质上还是数据。其中包括:
技术元数据:数据仓库的设计和管理人员用于开发和日常管理数据仓库时用的数据
业务元数据:业务赋予的描述属性
具体概念请看前置文章:【实战讲解】元数据管理落地实施
数据血缘
数据血缘是在数据的加工、流转过程产生的数据与数据之间的关系,它提供了一种探查数据关系的手段,用于跟踪数据流经路径。
数据血缘组成包括:
数据节点:数据流转中的每个实体,用于承载数据功能业务
节点属性:表名,字段名,注释,说明等
流转路径:节点间的流动方向
流转规则:记录流转路径过程中的操作内容
具体概念请看前置文章:【实战讲解】数据血缘落地实施
架构概览
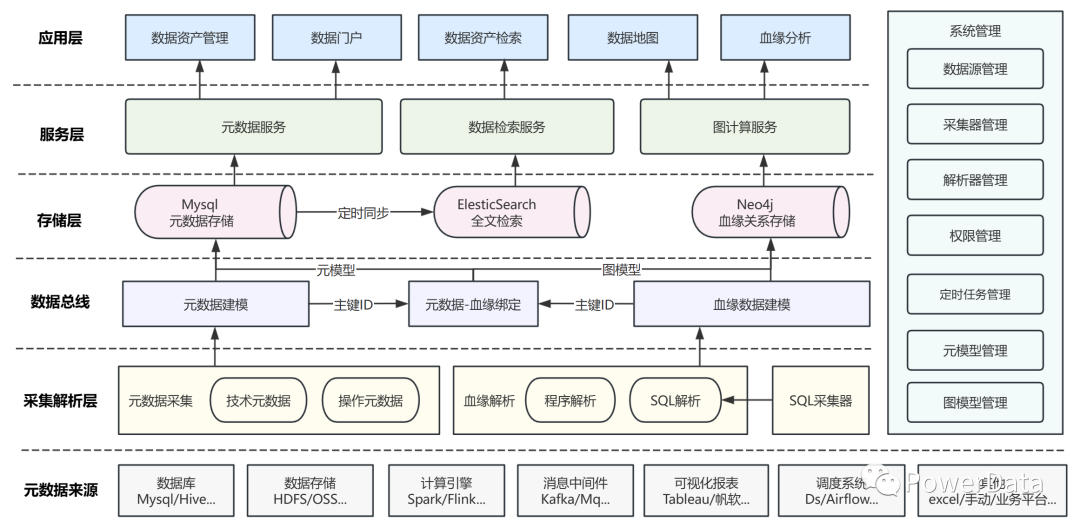 图:元数据与数据血缘应用架构 (配色有点多姿多彩...)
图:元数据与数据血缘应用架构 (配色有点多姿多彩...)
元数据与数据血缘的实现不仅是元数据采集与血缘解析,这些只是基础。
真正想要实现元数据和数据血缘并落地应用,要经过一系列流程包括元数据采集与血缘解析、元模型与图模型构建、落库存储、构建数据服务、实现基于元数据与数据血缘的数据应用。
接下来我们会按照上述应用架构,分层讲解元数据与数据血缘的实现流程。
元数据来源
元数据与血缘的底层数据来源主要为数据开发中常用到的数据组件。包括:
数据库:Mysql/Hive 等,获取数据的库表、字段、schema、索引、总数等元数据信息。
数据存储:HDFS/OSS 等,获取数据的存储路径、文件数等元数据信息。
计算引擎:Flink/Spark 等,可以提供数据开发作业的任务信息。同时可以获取 FlinkSQL、SparkSQL,解析对应表级血缘依赖。
消息中间件:Kafka/RocketMQ 等,可以提供当前数据的消息队列、主题、订阅者等元数据信息,对于数据血缘,消息中间件可以记录数据的传递路径节点。
可视化报表:Tableau/FineReport 等,可以提供报表、仪表盘、图表等元数据信息,对于数据血缘,可以记录报表的数据来源和关联关系。
调度系统:DolphinScheduler/Airflow 等,提供调度时间、调度评率、触发条件等元数据信息,通过可以获取调度系统内部的 SQL 脚本用于血缘解析。
其他:excel 文件 / 业务平台等,进行业务元数据的登记录入。
采集解析
元数据与血缘实现的核心层,也是技术难度与复杂度最高的一层。如何全方位地获取元数据信息,从而做成集成式一站式开发。如何从复杂繁多的组件中获取血缘关系并构建全流程数据血缘,希望本章能给你一些思路。
元数据采集
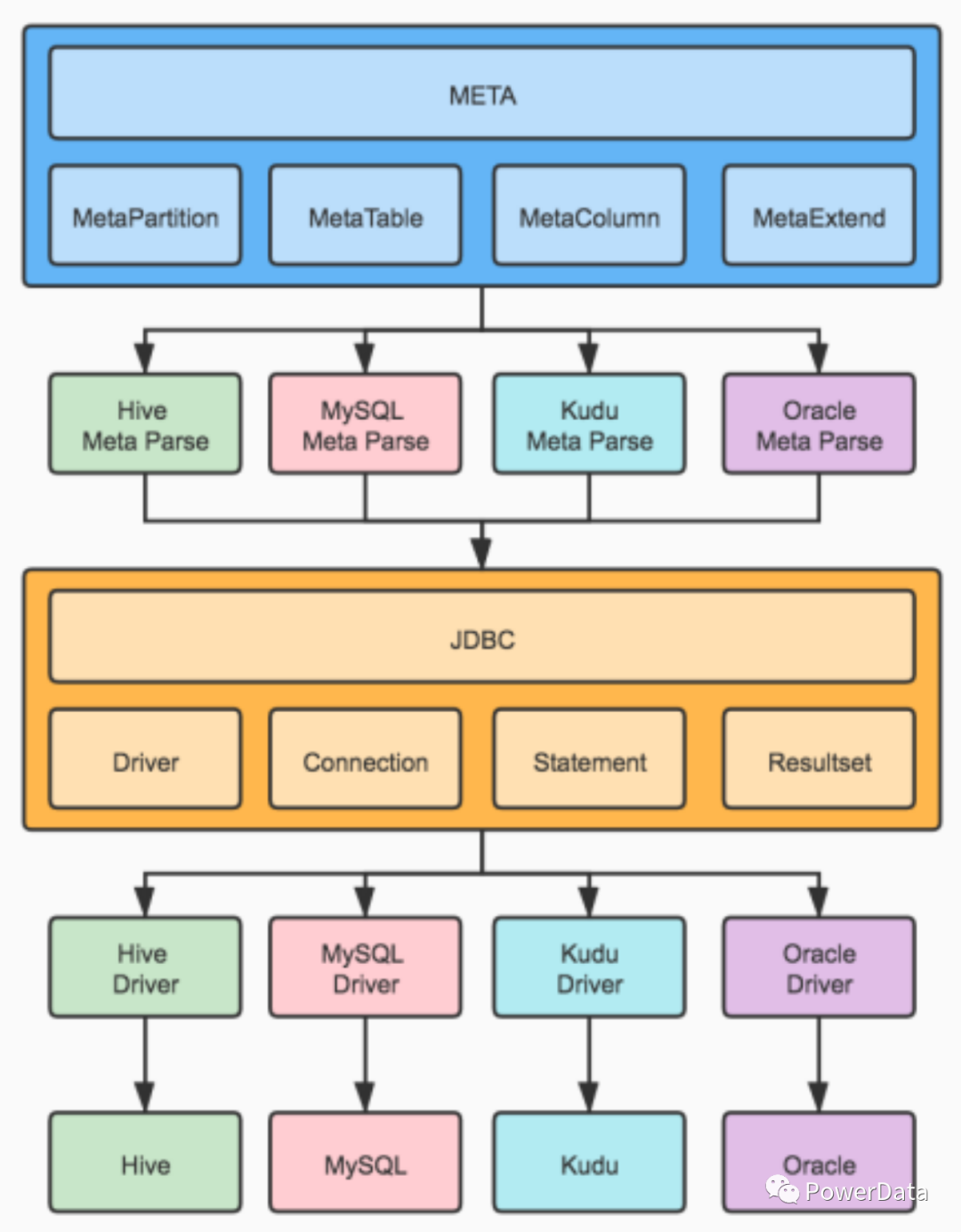 图:元数据采集示例
图:元数据采集示例
元数据采集主要包括以下内容:
主要采集对象
数据库、数据存储、调度系统、消息中间件等
采集手段
JDBC、HTTP、集成开发、登记录入等
采集频率
实时采集、定时采集、手动更新
采集粒度
库表级、任务级、字段级(费时费力不讨好,不推荐做这么细 / 手动狗头 / )
采集要求
完整性、准确性、可扩展性
JDBC
许多数据库系统都自带元数据查询命令,可使用 JDBC 连接并使用特定查询语句即可对目标库表的元数据进行查询。以 Hive 举例,可使用以下命令:
show partitions
describe “tables”
show create table
或者可直连对应组件的元数据库表例如 Hive 的 MetaStore 库,并进行查询。前提是对 MetaStore 的库表结构非常熟悉,能够准确的找到你想要查询的信息。
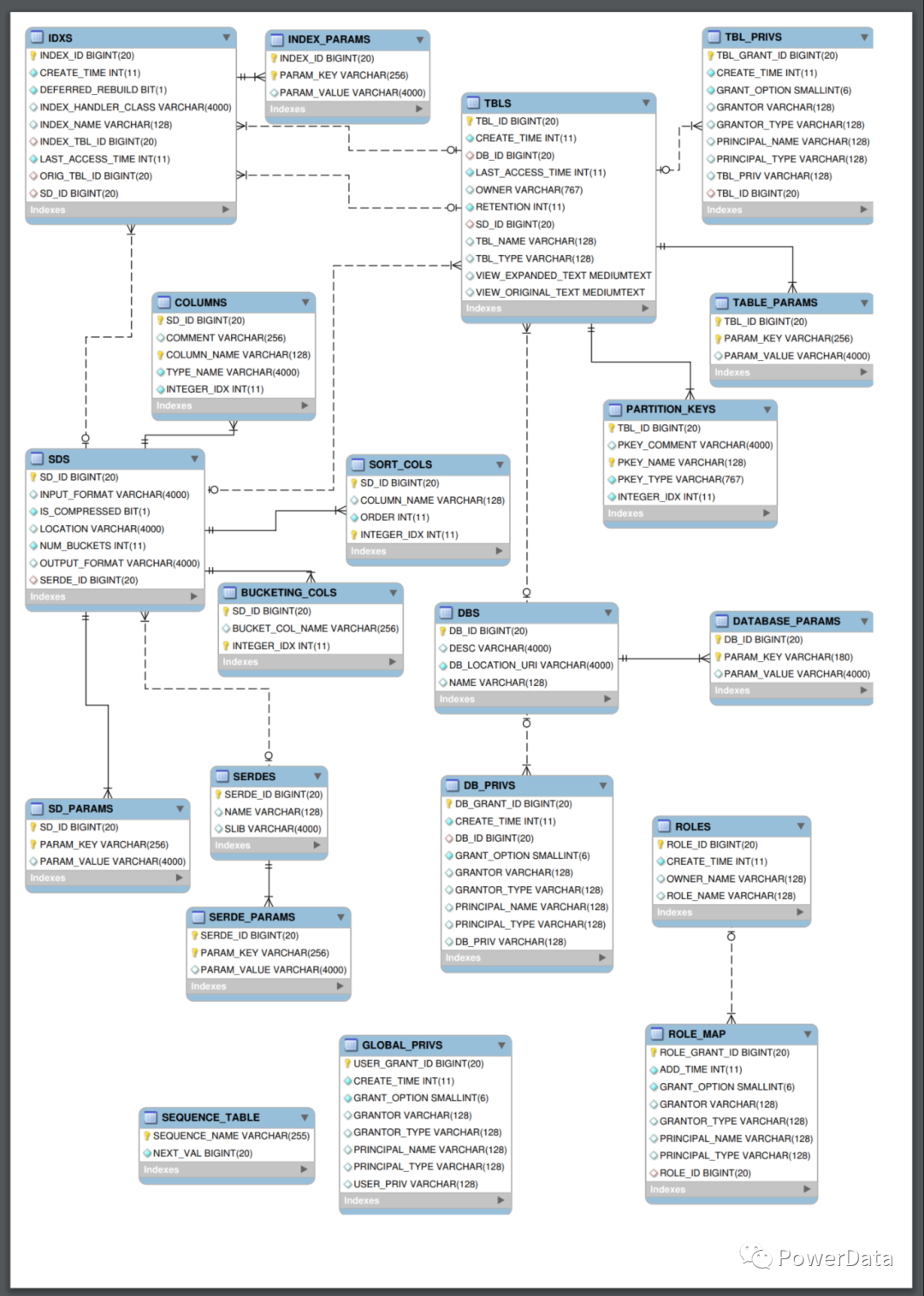 图:Hive MetaStore 关系图
图:Hive MetaStore 关系图
Rest API
可通 Rest API 获取具有前端页面的数据开发组件的元数据信息,例如 DolphinScheduler,Yarn,Flink。
这种方式快速便捷,所见即所得,而开发成本较低,直接 HTTP 请求就能获取目标元数据。但是数据成本的处理较高,因为得从多个接口返回的 json 格式中拼凑组合为最终结果,需要仔细梳理接口间的层级与数据关联关系~
以 DolphinScheduler 举例
DolphinScheduler 本地 API 文档地址
http://<master>:12345/dolphinscheduler/doc.html?language=zh_CN&lang=cn
获取所有项目信息
http://<master>:12345/dolphinscheduler/projects?pageNo=1&pageSize=100
根据项目名称获取所有工作流列表
http://<master>:12345/dolphinscheduler/projects/<project_name>/process-definition?pageSize=50&pageNo=1
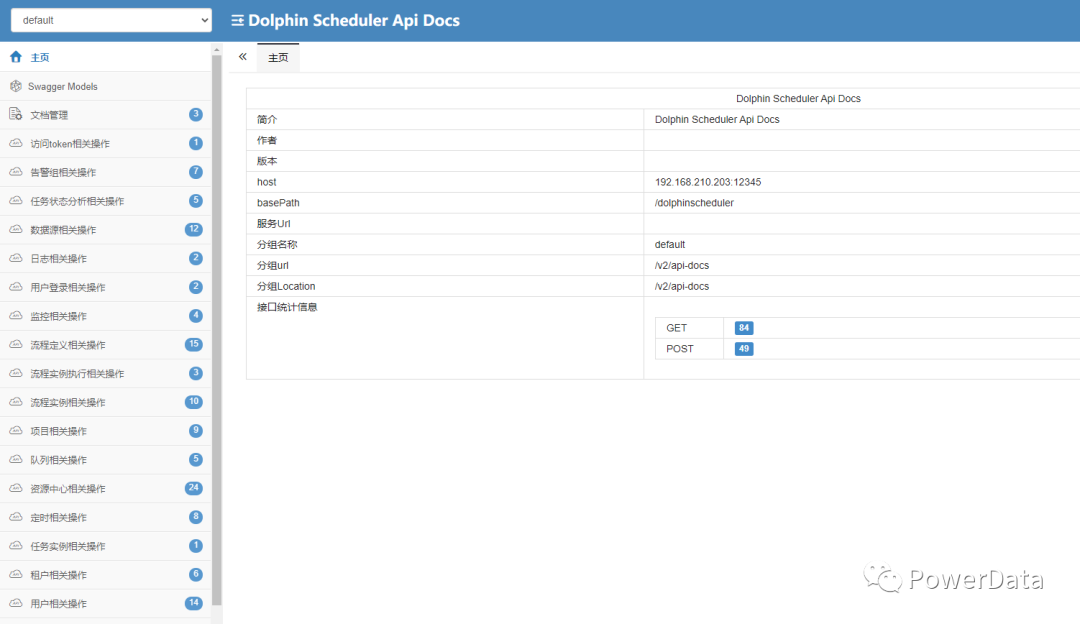 图:DolphinScheduler API 文档
图:DolphinScheduler API 文档 图:Flink REST API 说明
图:Flink REST API 说明
集成开发
集成开发主要是通过数据组件的 JAVA API 或客户端库,通过代码获取对应组件的元数据信息,适用组件范围最广,获取元数据信息最全的方式,包括 Hbase、Kafka、HDFS 等。
以 HDFS 举例
public class HDFSMetadataExample {
public static void main(String[] args) {
Configuration configuration = new Configuration();
configuration.set("fs.defaultFS", "<hdfs_uri>");
try (FileSystem fileSystem = FileSystem.get(configuration)) {
// 获取文件的元数据信息
Path filePath = new Path("<file_path>");
FileStatus fileStatus = fileSystem.getFileStatus(filePath);
// 获取文件路径并打印
System.out.println("File Path: " + fileStatus.getPath().toString());
// 获取文件大小并打印
System.out.println("File Size: " + fileStatus.getLen());
// 获取文件块大小并打印
System.out.println("Block Size: " + fileStatus.getBlockSize());
} catch (IOException e) {
e.printStackTrace();
}
}
}
登记录入
业务元数据的重要来源,在元数据与血缘平台构建完成后,可以通过平台进行业务元数据的登记与补全。
血缘解析
数据血缘核心节点为数据节点,同时还可包含任务节点、指标节点、报表节点、部门节点等任务流转与使用节点。所以我们不仅要对数据进行血缘解析,也需要对数据开发组件甚至业务系统开展程序解析,以此构建全流程数据血缘。
SQL 采集
SQL 是血缘解析的基础,SQL 来源包括调度系统、SparkSQL、FlinkSQL、本地 SQL 脚本、报表系统等,可通过元数据采集手段,将获取到的 SQL 用于 SQL 解析。
SQL 血缘解析
SQL 解析原理:
- 词法解析(Lexical Analysis):解析器会对输入的 SQL 语句从左到右读取并加载到解析程序,根据构词规则识别字符并切割成一个个的词条,将其拆分成一个个的词法单元(Token),如关键字、标识符、运算符、常量等, 例如 select name from tab 拆分词条如下:
 图:词条
图:词条
- 语法解析(Syntax Analysis):在词法解析的结果上,语法分析器使用语法规则和上下文无关文法(Context-Free Grammar)来验证结构是否符合语法规则,如果存在语法错误,解析器就会抛出相应的异常。如果适配成功则生成抽象语法树。
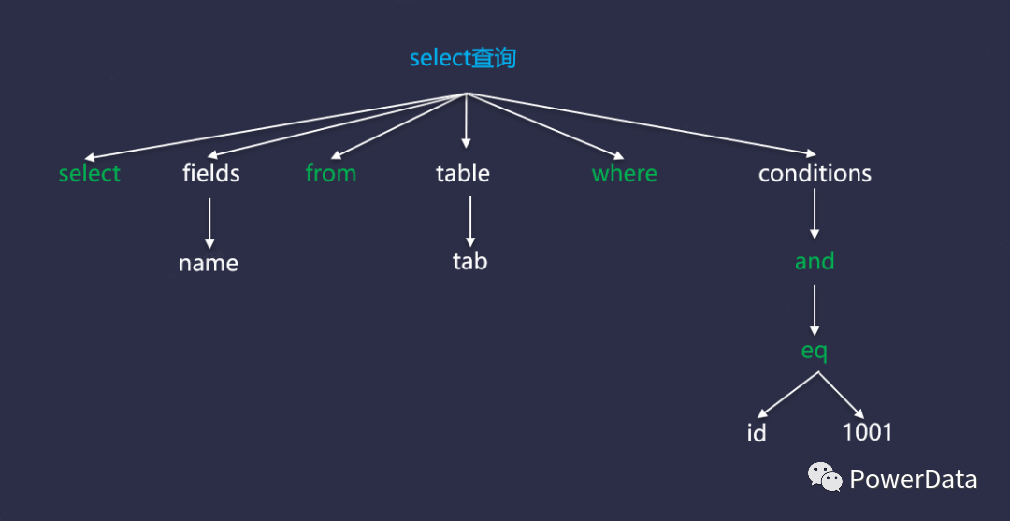 图:抽象语法树
图:抽象语法树
SQL 抽象语法树提供了一个抽象的、易于理解和处理的 SQL 表示形式,通过遍历和操作语法树,数据库系统可以分析 SQL 语句的结构、查询的意图和操作关系,可以获取当前 SQL 的血缘关系。
语义解析(Semantic Analysis):对语法解析得到的抽象语法树进行验证,确保字段、字段类型、函数、表等对象有效,检查列是否存在、数据类型的匹配性等,确保 SQL 语句中的表、列、函数等对象是有效和存在的。
查询优化(Query Optimization):在通过语法和语义分析之后,SQL 解析器将生成一个初始的查询计划(Query Plan)。然后,查询优化器会对初始查询计划进行优化。包括选择最佳的索引、重写查询以提高性能、决定连接顺序等。优化器的目标是生成一个效率最高的查询计划,以在执行阶段快速检索和处理数据。
查询执行计划生成(Execution Plan Generation):在优化阶段完成后,SQL 解析器会生成最终的查询执行计划。查询执行计划是一个指导数据库引擎执行查询的指令集。包括确定查询的数据访问路径、加入所需的操作符和算法等。
血缘解析原理:
通过开源的 SQL 解析器进行 SQL 解析,构建 SQL 抽象语法树。
通过 visitor 遍历语法树中各 table 与 column 节点。
将 table 节点为 insert、upsert、create 等作为目标节点,遍历获取子节点的字段。
将 table 节点为 select 作为来源节点,遍历获取子节点下的字段。
以目标节点为主,将来源节点绑定到目标节点中。
血缘解析组件推荐:
Apache Calcite-Alibaba Druid-JSQLParser:开源 SQL 解析器、可以直接将 SQL 解析为语法树对象,开发简易,上手快速,推荐此种方式。
Antlr:语法分析器、扩展性强、支持字段解析、开发门槛较高、不推荐。
SqlFlow:国外处理 SQL 关系的网站,支持字段级别血缘解析、同时支持开源李现部署,以 Rest API 方式提供 SQL 血缘解析服务。
Spline:Spark RDD 血缘解析组件。
程序解析
数据节点获取完成后,我们可以通过程序解析的方式获取各个数据流转与使用节点,例如: 调度任务节点、Flink/Spark 任务节点、报表节点、部门人员节点。通过程序解析的方式,构建各节点并与对应的数据节点进行绑定,形成数据全流程血缘。举个例子:
通过获取报表系统内部的权限,解析出每个报表绑定的部门、部门下面绑定的人员,然后在血缘中构建报表节点 -(绑定)-> 部门节点 -(绑定)-> 人员节点,同时报表来源为数仓,数仓数据是由 Flink 任务消费 Kafka 中的 Topic 进行获取的,Topic 数据是由业务表的 binlog 得来的,那么数据全流程血缘即为:
业务表 ->Kafka Topic->Flink application-> 数仓 -> 报表 -> 部门 -> 人员
数据总线
数据总线层对采集层数据进行汇总处理,并根据元模型与图模型对数据进行建模,将复杂的元数据结构和血缘关系数据转化为易于理解的形式,帮助更好的组织和理解数据,确保上层业务开展。
元数据建模
明确边界,梳理依赖关系,统一数据格式与存储方式。元数据建模后生成元模型。
流程:
沟通业务需求,明确采集边界:数据库 - 调度 - 中间件 - 报表 - 数据集成等
梳理组件架构,明确采集粒度:库 - 表 - 字段 - 视图,topic-partition - 副本
梳理依赖关系,确定业务主体:表 - partition - 流程节点 - datax 任务
构建主体对象,确定采集内容:具体需要采集哪些字段
汇总采集数据,填充主体信息:将采集的元数据,根据元模型进行填充
 图:元模型
图:元模型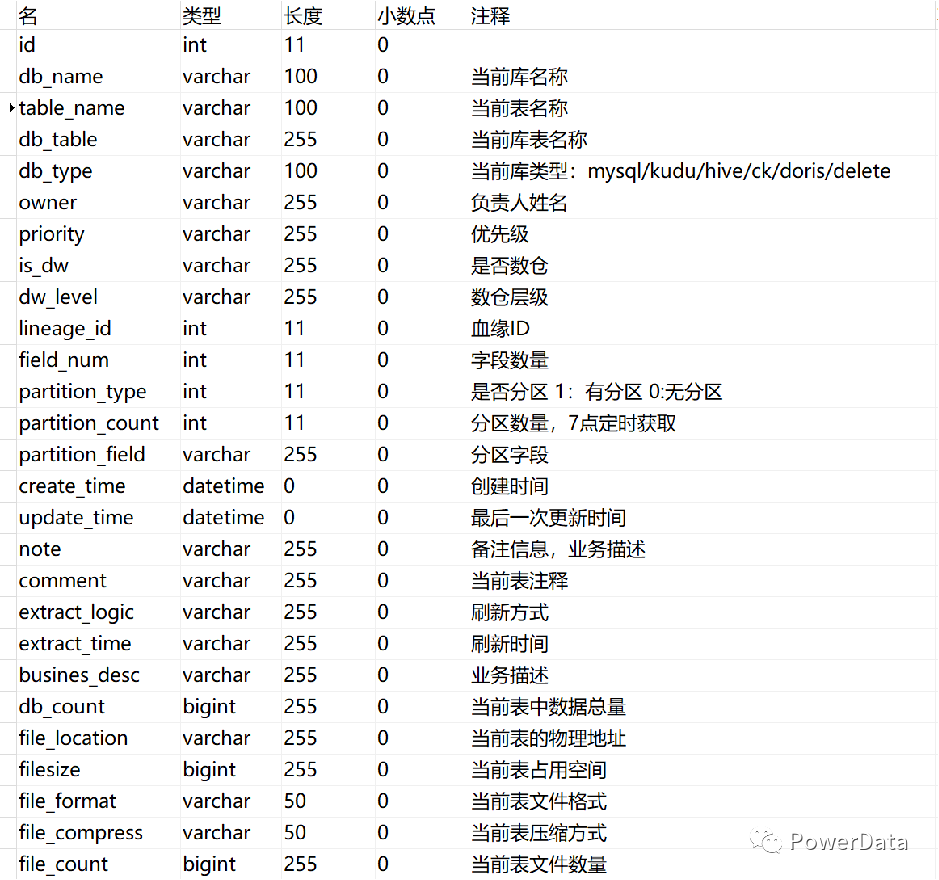 图:元模型字段
图:元模型字段
血缘数据建模
明确血缘节点类型,确定解析粒度,梳理节点依赖关系
流程:
明确血缘节点类型:数据库表 - 报表 - 人员
确定解析粒度:库 - 表 - 字段,组织 - 部门 - 人员,大屏 - 报表 - 指标
梳理节点属性:当前节点的属性信息
梳理节点依赖关系:节点层级依赖,血缘关系依赖
构建模型代码:通过 cypher 语句,构建 ORM 数据持久层代码
数据集成与汇总,填充节点属性信息信息、依赖关系
元数据血缘绑定
目的:构建以元数据为基础,血缘为抓手的应用方式,元数据记录需要与血缘节点绑定
流程:
构建全局唯一主键字段,建议采用 snowFlake 算法或现有全局 ID
确定元数据 - 血缘间绑定关系,通过主键字段进行绑定
业务开展过程中,用户可通过数据门户中的血缘关联,跳转至相关血缘节点, 也可在数据地图中,通过血缘节点直观探查元数据信息。
数据存储
数据存储包括元数据的存储与血缘数据的存储,元数据存储推荐用关系型数据库并同步至 ES 中,便于上层业务开发与数据资源的全文检索。血缘数据推荐使用图数据库,便于血缘关系的检索与图计算。
图数据库
介绍
在传统的关系数据库模型中,数据分布在多个表中,通过外键与关系表连接。查询数据关系时通常意味着连接多个表与索引。
图形数据应用图理论储存实体之间的关系信息,通过使用节点、边和属性来解释和管理数据。能够更加高效地应对处理复杂数据关系。
数据模型
节点:通常表示实体,比如用户、部门、商品等等, 类似于 RDBMS 中的一行记录
边:又被称为关系,由名称和方向组成,是图数据库中最重要的一个特征,在 RDBMS 中没有对应实现
属性:节点和边都可以有属性,类似 RDBMS 中的一个字段
图数据模型直接存储了数据节点之间的依赖关系,以边来表示节点之间的关系, 通过免索引邻接进行数据的组织,通过图查询语言进行数据检索。因为图数据模型是面向关系的,进行依赖关系查询时的操作与数据模型本身呈现高度一致性,性能极为高效。
免索引邻接
免索引邻接是指直接在点和边中保存相应点 / 边 / 属性的物理地址,直接进行寻址的遍历方法。免去了基于索引进行扫描查找的开销,实现从 o(logn) 到 o(1) 的性能提升。
免索引邻接使用遍历物理关系的方法查找,由于图中每个节点都有直接或间接指向其相邻节点的指针,查找只需要在关系链表中遍历,每次遍历成本为 o(1),它不会随着图数据量的增加而影响,仅仅和遍历所涉及到数据集大小有关,但是它需要占用较大的内存。
数据血缘选型
目前业内通常采用图数据库进行血缘关系的存储。
对于血缘关系这种层级较深,嵌套次数较多的应用场景,关系型数据库必须进行表连接的操作,表连接次数随着查询的深度增大而增多,会极大影响查询的响应速度。
而在图数据库中,应用程序不必使用外键约束实现表间的相互引用,而是利用关系作为连接跳板进行查询,在查询关系时性能极佳,而且利用图的方式来表达血缘关系更为直接。
服务层
数据 - 采集 - 解析 - 建模 - 存储都完成之后,就可以基于现有数据进行服务层的构建,主要是 Java 后台服务。对上层应用提供数据支撑。
元数据服务
提供元数据的增删改查服务
数据检索服务
意义:元数据产品必须提供高效简便的触达服务,才能够更好的发挥业务价值
作用:通过定期将 Mysql 库中的元数据信息抽取到 ES 中,提供全文检索服务,可以帮助业务人员快速定位所需数据资源。
方式:检索服务支持基于名称、基本属性、元数据间关系查找,并通过多种组合条件的模糊查询,即可在整个元数据环境中随时检索所需元数据。
图计算服务
数据血缘构建完成后,我们可以根据图数据库特性进行一些图计算分析服务,从不同层面查看数据的分布与使用情况,从而支撑业务更好更快更清晰。
例如:
数据节点下游节点数量排序,用于评估数据价值及其影响范围
查询当前节点的所有上游节点,用于业务追踪溯源
查询当前节点的所有下游节点,用于故障影响分析
数据节点输出报表信息详情统计,用于报表的上架与更新
查询孤岛节点,即无上下游节点的节点,用于数据删除的依据
通过核对上下游节点的安全等级与权限,进行安全审计工作
应用层
经过前期这么多的努力,我们终于到了应用层面,即通过元数据与数据血缘开展具体工作。让我们简单看看可以开展那些具体的工作吧。
**数据门户:**开发并维护一个数据门户网站,提供数据资产、数据地图、血缘关系、元数据可视化等服务。
**数据资产管理:**通过元数据信息建立数据资产清单并进行管理,包括数据集、数据表、字段、指标等信息。
**数据资产检索:**支持按关键字或标签搜索元数据信息,还可提供高级检索功能,如按数据类型、时间范围、血缘节点类型等条件进行筛选。
**数据地图:**构建数据地图,展示数据之间的逻辑及关联关系,可视化展示数据流程、数据传输路径和数据引用关系。
**血缘分析:**建立数据血缘分析应用,跟踪和记录数据的产生、转换和消费过程。分析血缘关系,驱动数据业务。
驱动业务
OK,上述所有步骤走完,我们才可以说是实现了元数据与数据血缘。那么它们能给我们带来哪些价值呢,即元数据与数据血缘如何驱动业务的开展。以下是我的简单总结:
数据节点定位,异常溯源恢复
支撑数据下架,辅助数据运维
数据价值评估
数据安全审计
全链路 - 自动化 - 数据质量
一站式数据资源查询
数据资产统计展示
数据标准化监控
梳理依赖关系,优化 ETL 路径
思考
元数据与血缘值得做吗
这个问题很好,做元数据与血缘之前大家可以好好思考一下问题的答案。以下是我的答案:
肯定值得做啊,对个人来说,元数据与血缘在实现的过程中,能够接触到很多新的技术点,包括:
血缘解析时你得去学习 SQL 解析
元数据采集时你要了解各个组件的基础原理并且进行数据对接
血缘存储要用的图数据库
等等以上内容都可以增加自己对大数据各组件广度与深度的了解。这是对于个人的收获。
对于团队来说,小团队就不说了哈,可能连元数据和血缘的概念都没有,就算有,一个 excel 搞定。但是超过 10 人的数据团队,元数据与血缘就很重要了,能够驱动数据业务开展就不提了,上一节中都有,提一些日常工作经常会遇到的问题吧。
入职新团队的快速上手:
进入一个新的数据团队,熟悉工作内容如果还靠文档或口口相传效率就太低了,直接把数据地图和数据门户甩过去,配合少量的讲解就能快速同步团队的数据信息与流转过程。
和研发与业务团队扯皮:
数据团队的工作重点之一,当研发团队不给你对的数据,业务团队说你给的数据不对,就会多方反复的扯皮推诿。
以后遇到这种情况,直接把 ods 层和 ads 层的元数据和血缘流转路径挨个拿出来对,看看到底是研发源头数据出了问题(增添删改了数据格式,或者数据重复等等),还是数据团队在同步和流转过程中处理出错(ETL 操作问题、调度问题、数据读取写入问题等等),还是业务团队没用好没用对数据(不理解数据含义、数据口径未对齐等)。
数据团队的价值体现
数据团队的工作难点之一,如何量化我们的产出,给老板持续画饼,加强对数据团队的资源投入。这事儿光靠嘴上说没用啊,你得拿出东西来,什么东西呢,大屏(老板的最爱 / 手动狗头 / ),直接拿元数据和血缘数据做个大屏,其中包括但不限于:
元数据统计展现:统计展示目前数据团队接入管理了多少张表、多少个字段、多少条数据、多少存储空间等等。
元数据变更记录折线图:当前元数据做了哪些操作修改,能够直观的反应数据团队的工作量。
数据覆盖率:什么意思,即当前元数据与血缘平台纳管公司内部所有数据的比例(不仅仅是数据团队的内部数据,还包括研发数据、各部门业务平台数据、公司运营数据等等),这是对元数据与血缘的应用情况考核,也是加强数据团队话语权的指标,有了这个加上目前已经做出来的效果,就能向 boss 申请更多的操作权限,去规范整个公司的数据流转与运作了。
血缘节点类型饼图:把当前血缘纳管的数据节点类型,包括表节点、指标节点、报表节点、数据操作人节点、调度节点等等,进行饼图统计
字段血缘是不是伪需求
是,别做,费时费力还不讨好。
具体原因王春波老师已经说的很明确了,大家可以点击查阅:《字段级血缘分析就是一个伪需求》
SqlBoy 不懂代码,能开发元数据和血缘嘛
不懂代码还想搞开发,Java 赶紧学起来嗷。
想要加入社区或对本文有任何疑问,可直接添加作者微信交流。
图:作者微信
我们是由一群数据从业人员,因为热爱凝聚在一起,以开源精神为基础,组成的 PowerData 数据之力社区。
可关注下方公众号后点击 “加入我们”,与 PowerData 一起成长